Understanding JS Prototypes: From Prototype, Prototype Chain to Prototype Pollution
Introduction
Recently, I've been reading 《Beyond XSS: Exploring the Web Frontend Security Universe》, a frontend security book written by Huli. I never expected to encounter Prototype Chain in a security book... It felt like meeting a familiar stranger, since I review it every time I prepare for an interview, but always have a vague understanding after time passes. This is mainly because I've never structured my understanding and documentation, so I decided to write this article. Besides helping me gain a more structured understanding, it can also serve as a reference for those who need it.
This article will start with Prototype, then introduce Prototype Chain, and will also cover Prototype Pollution that I learned from "Beyond XSS". It will include:
- Starting with ECMAScript constructors and prototypes
- The Prototype Chain connected by
[[Prototype]] - Applications and considerations for Prototype Chain
- Unexpected use in attacks! A brief introduction to Prototype Pollution
- Methods to prevent Prototype Chain pollution
- Summary and practical takeaways
I hope readers will gain a better understanding of Prototypes, not just for interviews, but more importantly, to understand what to be mindful of in actual development.
Since the content is quite extensive, the final summary section will review the key points of this article through briefly answering several questions, including:
- What is a Prototype
- What is a Prototype Chain
- What is Prototype Pollution
- Practical actions to take
Now, let's begin this journey into Prototypes!
Starting with ECMAScript Constructors and Prototypes
Many articles discussing JS Prototypes start with OOP class concepts or inheritance, but I feel this isn't very intuitive for pure frontend developers (i.e., those who transitioned to become frontend engineers). So, we can completely ignore the class concept for now, as JS originally didn't have class concepts.
So where should we start to understand Prototype? Perhaps from the source, by looking for relevant content in the ECMAScript specification. In this Spec, I found a simple definition of prototype:
prototype: object that provides shared properties for other objects
There seem to be two key points:
prototypeis an object- The purpose of
prototypeis related to "sharing" properties, which other objects can use
There are a few more sections that provide more information:
When a
constructorcreates an object, that object implicitly references the constructor'sprototypeproperty for the purpose of resolving property references.
This means that when an object is created through a constructor, that object implicitly references the constructor's prototype property. Here we need to understand what a constructor is. According to the document, the definition of constructor is:
constructor: function object that creates and initializes objects The value of a constructor'sprototypeproperty is a prototype object that is used to implement inheritance and shared properties.
According to this definition, we can understand:
- A
constructoris a function used to create objects, specifically using aconstructorwithnewto create object instances - The
prototypeproperty of aconstructorallows objects created to share properties.
The text alone is too abstract, so code will help us understand better. Let's start by explaining 1. with a demonstration of constructor and new:
// This is a constructor function `Person`, this refers to the created object
function Person(name, age) {
this.name = name
this.age = age
}
const yi = new Person('yi', 28) // Create yi using new
console.log(yi) // Person {name: 'yi', age: 28}
const winnie = new Person('winnie', 64) // Create winnie using new
console.log(winnie) // Person {name: 'winnie', age: 64}
From the code above, we can see that by declaring a constructor function for creating humans, we can new up two humans, yi and winnie, each with their own name and age.
Next, let's explore point 2. mentioned earlier about how the prototype property of a constructor allows created objects to share properties.
Since all humans can speak, we want all created human instances to share a said method. This can be expressed in code as follows:
function Person(name, age) {
this.name = name
this.age = age
}
// Through the prototype property of constructor Person
// All objects created with new share the said method
Person.prototype.said = function (text) {
console.log(`${this.name}: ${text}`)
}
const yi = new Person('yi', 28)
console.log(yi.said('Hello World!')) // yi: Hello World!
const winnie = new Person('winnie', 64)
console.log(winnie.said('Hello World!')) // winnie: Hello World!
By now we should understand constructor and prototype:
- constructor: is an object function that can be used with
newto create object instances, and the created object instances automatically inherit properties fromconstructor.prototype - prototype: is a property within the
constructorobject, which is itself an object, and its properties will be inherited by object instances created based on theconstructor
You can see the explanations of these two concepts are complementary and inseparable.
Also, this type of object instance created by new inherits properties from constructor.proptotype, which can also be called Prototypal Inheritance.
p.s. ECMAScript content is continuously updated, so it may be different in the future.
The Prototype Chain Connected by [[Prototype]]
Although we now know that winnie.said points to Person.prototype.said, a key question remains unanswered:
How does the code or the JS engine know that winnie.said should point to Person.prototype.said?
Since winnie is an object, theoretically, when calling winnie.said, it should return undefined if it doesn't find said, right? The reason it doesn't do this must be because the program performs some logical checks in the background. What might those logical checks be?
Let's first print out winnie to see what it contains:
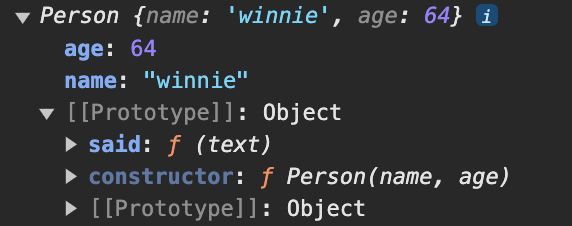
We discover that the winnie object has an implicit [[Prototype]] object, which contains the said function, exactly the function from Person.prototype.said!
Looking closer, we can also see that [[Prototype]] contains constructor: ƒ Person, which actually indicates that the winnie object was constructed by Person.
Furthermore, it means that the prototype object [[Prototype]] of winnie inherits from Person's prototype, which is Person.prototype.
So when winnie.said is executed, the logic triggered would be:
- First, look for
saidin thewinnieobject itself; if found, return it, otherwise look in its prototype object - Look in the
[[Prototype]]prototype object ofwinnie, findsaid, and return it
At this point, you might think that you can find Person.prototype.said through winnie.[[Prototype]].said, right?
winnie.[[Prototype]].said === Person.prototype.said
// `SyntaxError: Unexpected token '['`
Unfortunately, this doesn't work. If you execute winnie.[[Prototype]].said, you'll only get a SyntaxError: Unexpected token '[' error. This is because [[Prototype]] is a private internal property of JS and cannot be directly accessed or used. However, there are other ways for developers to get the prototype object:
Object.getPrototypeOf(object): This is the standard method defined in ECMAScript. Through this method, you can obtain the prototype object of an objectobject.__proto__: This is implemented in most browsers but is a "non-standard" approach. If you search in the ECMAScript documentation, you'll find that it's a deprecated item, so in actual development, it's better to use the standard methodObject.getPrototypeOfto look for prototype properties and methods
You can verify these two methods with code:
// Get Object.getPrototypeOf(winnie) and prove it points to Person.prototype
Object.getPrototypeOf(winnie) === Person.prototype // true
Object.getPrototypeOf(winnie).said === Person.prototype.said // true
// Get winnie.__proto__ and prove it points to Person.prototype
winnie.__proto__ === Person.prototype // true
winnie.__proto__.said === Person.prototype.said // true
Of course, we can also verify if winnie.said points to the prototype object:
// Verify winnie.said points to the prototype object Person.prototype.said
winnie.said === Person.prototype.said // true
Now, let's look at an interesting execution. What would be returned if we execute winnie.valueOf?
You might think it would be undefined, since neither the winnie object itself nor the Person.prototype prototype have valueOf, so it should return undefined, right?
That's not the case. It will actually return ƒ valueOf(). Where does this function come from?
The answer can be found in the following image:
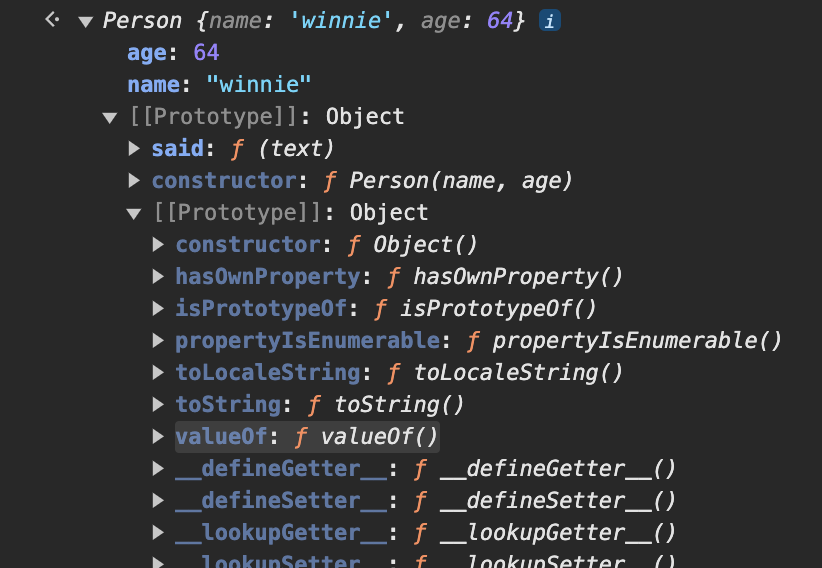
We discover that in the prototype object [[Prototype]] created by constructor Person, there still exists an upper-level [[Prototype]], and when expanded, we can see the valueOf function within it!
So the logic when executing winnie.valueOf is:
- First, look for
valueOfin thewinnieobject itself; if found, return it, otherwise look in its prototype object - Look in the
[[Prototype]]prototype object ofwinnie; if found, return it, otherwise look in an even higher-level prototype object - Look in the higher-level
[[Prototype]]ofwinnie's[[Prototype]]prototype object; if found, return it. Thus, it findsvalueOfand returns it. Note that this[[Prototype]]has aconstructorofƒ Object, which is JS's built-in Objectconstructor
// Verify winnie.valueOf points to Object.prototype.valueOf
winnie.valueOf === Object.prototype.valueOf // true
// This actually means that winnie's prototype's prototype points to Object.prototype
winnie.__proto__.__proto__ === Object.prototype // true
winnie.__proto__.__proto__.valueOf === Object.prototype.valueOf // true
The examples above are cases where "a result is found". Is it possible that a result is not found?
Yes, when something is not found and there is no higher-level [[Prototype]] (i.e., [[Prototype]] is null), it will return undefined.
For example, when executing winnie.notDefinedOf, the logic is:
- First, look for
notDefinedOfin thewinnieobject itself; if found, return it, otherwise look in its prototype object - Look in the
[[Prototype]]prototype ofwinnie; if found, return it, otherwise look in an even higher-level prototype object - Look in the
[[Prototype]]ofwinnie's[[Prototype]]; if found, return it, otherwise look in an even higher-level prototype object. It finds that there is no higher-level[[Prototype]]content, so it returnsundefined
/** Conceptual demonstration flow */
// Discover winnie has no notDefinedOf, then look in higher-level prototype
winnie.notDefinedOf ->
// Still no notDefinedOf property, then look in higher-level prototype
winnie.__proto__.notDefinedOf ->
// Still no notDefinedOf property, then try to look in higher-level prototype
winnie.__proto__.__proto__.notDefinedOf ->
// Discover higher-level prototype returns null, so stop
// Finally winnie.notDefinedOf result returns undefined
winnie.__proto__.__proto__.__proto__ // null
This "process" of looking for object properties in [[Prototype]] is actually the Prototype Chain.
A more complete explanation of the Prototype Chain:
When calling an Object Data property, if that property is not found, it will look in its Prototype object. If found, it returns the value corresponding to the property; if not found, it will look in the higher-level Prototype object of the Prototype object. This logic is repeated until the property is found and its corresponding value is returned, or until the Prototype object is
null, meaning there is no higher-level Prototype object content, at which point it returnsundefined. This process is the Prototype Chain.
This is a conceptual explanation, and I believe as long as the concept is correct, any phrasing is fine, such as:
When calling an Object Data property, if that property is not found, it will look in the object's
__proto__. If found, it returns the value corresponding to the property; if not found, it will look in the__proto__of the__proto__. This logic is repeated until the property is found and its corresponding value is returned, or until the called__proto__isnull, at which point it returnsundefined. This process is precisely the Prototype Chain.
Here, Object Data refers to data of object type, such as objects and arrays.
In fact, frontend developers use the Prototype Chain almost every day. For example, when calling [...].filter, they are calling the prototype object method of the Array object, which is the Array.prototype.filter function.
An interesting question is: data like strings or numbers are not object types but primitive types, so they shouldn't have [[Prototype]]. Why can they have their own methods like "hello".toUpperCase()?
The reason is that when executing "hello".toUpperCase(), the JS engine will first create a temporary object instance of "hello" through something like new String("hello"). This way, it can call String.prototype.toUpperCase().
Applications and Considerations for Prototype Chain
So far, we've broadly understood Prototype, Prototypal Inheritance, and Prototype Chain, and know that every time we develop, we can call native methods of Object or Array because of the Prototype Chain.
So, are there other applications for the Prototype Chain?
Quite intuitively, it's when developers need instances created by new to "share" specific properties, like this:
// constructor Dog
function Dog(name){
this.name = name
}
// Use prototype to make objects instantiated by new Dog bark
Dog.prototype.bark = function(voice) {
console.log(voice)
}
const dogA = new Dog('肚子')
const dogB = new Dog('吐司')
dogA.bark('旺旺') // '旺旺'
dogB.bark('嗚嗚') // '嗚嗚'
console.log(dogA.bark === dogB.bark) // true, both come from the prototype object
You might wonder, can't we just write this.bark=function(voice){...} in Dog? Isn't it the same?
Let's try:
// constructor Dog
function Dog(name){
this.name = name
// Try another way to insert bark into each dog instance created by new
this.bark = function(voice) {
console.log(voice)
}
}
const dogA = new Dog('肚子')
const dogB = new Dog('吐司')
dogA.bark('旺旺') // '旺旺'
dogB.bark('嗚嗚') // '嗚嗚'
console.log(dogA.bark === dogB.bark) // false, different memory addresses!
In terms of "functionality," they are indeed the same, but in terms of "memory," they are different. This means more memory will be occupied. Of course, if the data volume is small, the difference is negligible. However, the larger the data volume, the greater the impact. So in these scenarios, it's recommended to use the Prototype characteristic.
To add a bit more context, the difference in memory address mainly manifests in Object type data, such as objects, arrays, functions, etc. If it's pure strings or numbers, there's no memory difference between the two. Feel free to reference JS Variable Passing Exploration: pass by value, pass by reference, or pass by sharing? or Google keywords like JS Primitive Data vs Object Data for more information.
Additionally, JS's class syntax sugar, with its inheritance concept, is actually implemented using the Prototype characteristic, but since this article doesn't discuss class, I'm just mentioning it briefly.
In short, the concept of inheritance is widely applied in programming, and JS uses the Prototype characteristic to implement this concept.
It sounds great, but are there any drawbacks or things to note? Of course there are.
The general concept is similar to being careful when using "shared data or functions" because the scope of influence can be significant. Without proper testing, it's easy to encounter situations where changing A breaks B. With Prototype, such situations can be even more severe. Unlike general shared functions, where developers have to "manually import" the function to use it, Prototype properties "automatically inherit" function features, so they are more likely to cause bugs unconsciously.
Here are some considerations for Prototype:
1. Avoid Modifying the Content of Native Prototypes!
The most important point is to "avoid modifying the content of native JS Prototypes" because it affects almost all calls to that object data, making it completely unpredictable and hard to maintain.
Here's a random example:
// Suppose developer A adds a method toObjectString to Object.prototype
Object.prototype.toObjectString = function() {
return JSON.stringify(this);
};
// Developer A thinks everyone can use it conveniently now! Like this:
const person = { name: 'Alice', age: 25 };
console.log(person.toObjectString()); // {"name":"Alice","age":25}
// But such a modification actually affects all other objects and may produce unexpected behavior
// For example, when developer B uses a for...in loop
const data = { a: 1, b: 2, c: 3 };
for (let key in data) {
// Developer B expects to print a, b, c in sequence
// But, the result will be a, b, c, toObjectString
console.log(key); //
}
How should we handle cases like this better? Just make an independent "shared function" transObjToString(obj). When you need to use it, just import this shared function, and it's also easy to write unit tests for.
There's another issue with the above example: if browsers actually implement a toObjectString function in Object.prototype in the future, and its logic is different from what developer A implemented, then all parts of the project using it might break.
I emphasize again: In almost all cases, you don't need to modify the native JS Prototype Chain. I've encountered projects with legacy code that embedded things in the native Prototype Chain, which is really troublesome.
By the way, ESLint has rules to prevent developers from modifying the native JS Prototype Chain, such as no-extend-native, which is quite useful.
Have you noticed I wrote "in almost all cases," implying that in some cases, you might actually need to modify the native JS Prototype Chain?
Yes, if your project needs to use native JS methods that are "supported by most browsers but not by a few," you might consider this approach. For example, suppose Array.prototype.map can be used in most browsers but not in a mysterious browser, and your project must support it. You might consider adding some conditions to Array.prototype.map, using if to handle the mysterious browser and else for the native JS logic.
In short, only when dealing with compatibility issues should you "slightly consider" tampering with the JS Prototype Chain.
The last section of MDN: Inheritance and the prototype chain contains a related warning:
the native prototypes should never be extended unless it is for the sake of compatibility with newer JavaScript features.
To conclude this section, I want to say that even for compatibility issues, you can find other ways to handle them. It's best not to touch the native Prototype Chain if possible!
2. Avoid Creating an Excessively Long Prototype Chain
In simple terms, an excessively long Prototype Chain might cause performance issues. The reason is easy to understand: each step of looking up in a higher-level prototype object requires running a piece of program logic. If there are too many steps, it will take more time to process.
To practically feel this, you can write a function that "simulates" the lookup process in the Prototype Chain:
function findPropertyInPrototypeChain(obj, property) {
let currentObj = obj;
while (currentObj !== null) {
// hasOwnProperty can confirm if the obj itself has a specific property
// If found, it means success, directly return the property value
if (currentObj.hasOwnProperty(property)) {
console.log(`Found '${property}' in object.`);
return currentObj[property];
}
// If not found, it means we need to look up in a higher-level prototype object
console.log(`Property '${property}' not found. Moving up the prototype chain...`);
currentObj = Object.getPrototypeOf(currentObj);
}
console.log(`Property '${property}' not found in any prototype level.`);
return undefined;
}
Just looking at this findPropertyInPrototypeChain, we can see that the time complexity is O(n), where n represents the length of the Prototype Chain. Therefore, it can be said that the Prototype Chain is related to performance.
Usually, the actual judgment logic is more complex, possibly considering environments and other factors. In short, even this simple simulated logic can verify that if the Prototype Chain is too long, it will indeed make performance worse.
3. Avoid Modifying the Prototype Chain Everywhere
It's recommended to modify the Prototype Chain of a constructor in only one place, otherwise it might lead to unpredictable situations:
// constructor Dog file
export function Dog(name, nickName){
this.name = name
this.nickName = nickName
}
Dog.prototype.bark = function(voice) {
console.log(voice)
}
// Modify prototype bark in file A
import Dog from '...'
Dog.prototype.bark = function(voice) {
console.log(`${this.name}: ${voice}`)
}
// Modify prototype bark in file B
import Dog from '...'
Dog.prototype.bark = function(voice) {
console.log(`${this.nickName}: ${voice}`)
}
// Use prototype bark in file C
import Dog from '...'
const dogA = new Dog('肚子', '小肚')
dogA.bark('旺旺') // ??, unpredictable result, depends on the content of Dog.prototype.bark executed last
It's best to define the behavior of Dog.prototype.bark in the initial Dog file. If you really need to modify or optimize it, do it at this single source, which better avoids unpredictable situations.
Unexpected Use in Attacks! A Brief Introduction to Prototype Pollution
Up to this point, we've covered most of the concepts you need to know about Prototype, especially the important part about "avoiding" doing anything to the Prototype Chain. Often, knowing what not to do is much more important than knowing what to do.
Next, I'll discuss Prototype Pollution concepts and cases that I learned from reading 《Beyond XSS: Exploring the Web Frontend Security Universe》. This is my personal output after learning, but it's only a "brief introduction." If you want to understand it deeply, I recommend buying the original book. The book not only covers Prototype Pollution but also many unexpected web attack/defense techniques. While the amount of knowledge is substantial and not limited to frontend engineering, making it not easy to understand, it's really quite interesting. If you are someone with about two years of frontend engineering experience (which I think is a reasonable initial knowledge level) and are interested in security issues, it would be quite suitable for you to read.
Enough book promotion, let's get to the main topic: what is Prototype Pollution?
Prototype Pollution refers to when attackers use methods like code injection to modify the prototype of prototype objects, thereby affecting the behavior of all objects that inherit from that prototype, creating security vulnerabilities. When combined with the execution of other code, it can further lead to unexpected attacks.
Here, we can divide what attackers must do into at least two parts:
- The attacker will try to find "ways to pollute the Prototype Chain," creating security vulnerabilities
- The attacker also needs to find "what content to pollute," and when the polluted content is combined with the execution of other code, it can produce actual attacks
Let's first look at point 1, finding ways to pollute the Prototype Chain. Suppose there's a piece of code in a project:
// Declare a merge function to merge two objects
function merge(target, source) {
for (let key in source) {
if (typeof source[key] === 'object') {
target[key] = merge(target[key] || {}, source[key]);
} else {
target[key] = source[key];
}
}
return target;
}
// Normal use of merge seems fine
const styleConfig = { theme: 'light' };
const newStyle = { fontSize: 14 }
merge(styleConfig, newStyle);
console.log(styleConfig); // {theme: 'light', fontSize: 14}
Now there's a feature that allows users to update style configurations through custom JSON config input. The approximate code is as follows:
......omitted
<body>
<!-- Demo feature for inputting JSON style configuration -->
<h2>Input Custom JSON Style:</h2>
<textarea id="configInput">{ "theme": "light" }</textarea>
<button id="applyButton">Submit Config</button>
<div id="configResult"></div>
<!-- Used to display whether Object.prototype.isPolluted is successfully polluted -->
<button id="checkPollutedResultButton">Check Pollution</button>
<div id="checkPollutedResult"></div>
<script>
function merge(target, source) {
for (let key in source) {
if (typeof source[key] === "object") {
target[key] = merge(target[key] || {}, source[key]);
} else {
target[key] = source[key];
}
}
return target;
}
// Used to submit the latest custom style
function applyConfig() {
const configInput = document.getElementById("configInput").value;
const config = { theme: "default" };
merge(config, JSON.parse(configInput));
const configResult = `Latest configuration result: ${JSON.stringify(
config,
null,
2
)}`;
document.getElementById("configResult").textContent = configResult;
}
// Function to check if Object.prototype.isPolluted has been successfully polluted
function checkPollutedResult() {
document.getElementById(
"checkPollutedResult"
).textContent = `Object.prototype.isPolluted value: ${Boolean(
Object.prototype.isPolluted
)}`;
}
document.addEventListener("DOMContentLoaded", function () {
document
.getElementById("applyButton")
.addEventListener("click", applyConfig);
document
.getElementById("checkPollutedResultButton")
.addEventListener("click", checkPollutedResult);
});
</script>
</body>
......omitted
Now the attacker's goal is to find a way to "pollute the Object Prototype."
Since this is a demonstration, I've added a section of code related to checkPollutedResult. If Object.prototype.isPolluted is successfully polluted, clicking checkPollutedResultButton will display a result of true.
So how can we pollute properties within Object.prototype?
By observing the code, we can see that the merge function has logic for target[key] = source[key]. If it can be executed as obj.__proto__.isAdmin = true, the goal can be achieved! This is because obj.__proto__ points to the prototype object's prototype.
At the same time, this demo App itself has an input field for input, and the input value is passed as the source parameter to merge. Let's look at merge again:
function merge(target, source) {
for (let key in source) {
if (typeof source[key] === "object") {
target[key] = merge(target[key] || {}, source[key]);
} else {
target[key] = source[key];
}
}
return target;
}
We can see that it just integrates source into target. Suppose we pass in { "__proto__": "64" }, it would go through the logic of target[__proto__] = "64", and since "64" is not an "object", it ends there.
But if the input value is { "__proto__": { "isPolluted": true } }, since { "isPolluted": true } is an "object", it would be passed into merge again as the source parameter, eventually going through the process of target["__proto__"]["isPolluted"] = true!
Therefore, when the input JSON contains { "__proto__": { "isPolluted": true } }, it can successfully pollute Object.prototype.isPolluted. You can see the test screen below:

In this case, the attacker can input { "__proto__": xxx } in the input field and verify whether the pollution was successful by printing Object.prototype in the browser.
If it's confirmed that pollution can be successful, we move on to the second stage: finding what content to pollute. When the polluted content is combined with the execution of other code, it can produce actual attacks.
Here's another demo case (link and code provided below) with logic that differs from the previous one in:
- Adding user identity, and initially making an API call to get the user's admin status, BUT simulating a situation where the API call fails
- Adding a button to delete configuration, which only appears when the user is an admin
- Adding logic to store custom config in localStorage, so users can see their custom config from the last operation after the page renders
The code is more complex than before. If you have time, you can first try the demo-prototype-pollution exercise link to see if, without directly modifying CSS, you can figure out what operations to perform to achieve the attack of "making the 'delete configuration button' that wouldn't normally be displayed due to permission restrictions appear."
p.s. This demo case is designed with a major vulnerability for "frontend engineers," aiming to let frontend engineer readers easily play around and better understand Prototype Pollution. Actual project code would be much more complex, and many would involve areas outside frontend engineering, such as API interactions.
If you don't have time or don't want to play, you can read on. First, here's some code commentary:
......omitted
<body>
<!-- Demo feature for inputting JSON style configuration -->
<p>Try to figure out how to make the "Delete Config" button appear through data input and other operations. You can't directly modify CSS.</p>
<h2>Input Custom JSON Style:</h2>
<textarea id="configInput"></textarea>
<button id="applyButton">Submit Config</button>
<!-- This delete configuration button only appears if the user has admin rights (true) -->
<button id="deleteButton">Delete Config</button>
<div id="configResult"></div>
<script>
// Declare an empty object as space for user data access
const user = {};
// Simulate a getUserAdmin API request, but with a failed scenario
function sendUserAdminApiRequest() {
return new Promise((resolve, reject) => {
setTimeout(() => {
reject(new Error("API request failed"));
}, 2000);
});
}
// Make an API call to retrieve user admin data
function getUserAdminData() {
sendUserAdminApiRequest()
.then((response) => {
// If the API succeeds, it adds the Admin status
user.isAdmin = response;
renderDeleteButton();
})
.catch((error) => {
// If the API fails, it prints a failure message
console.error("API request failed:", error.message);
});
}
// Function to merge objects, which is a vulnerability that can pollute Prototype
function merge(target, source) {
for (let key in source) {
if (typeof source[key] === "object") {
target[key] = merge(target[key] || {}, source[key]);
} else {
target[key] = source[key];
}
}
return target;
}
// Function to check if data is valid JSON
function isValidJSON(jsonString) {
try {
JSON.parse(jsonString);
return true;
} catch (e) {
return false;
}
}
// Responsible for rendering the delete button, only displayed if user is admin
function renderDeleteButton() {
const deleteButton = document.getElementById("deleteButton");
deleteButton.style.display = user.isAdmin ? "inline-block" : "none";
}
// Responsible for rendering custom style results, including:
// 1. If newConfig is not passed in, set moreConfig to content retrieved from localStorage
// 2. Finally, use merge to combine config and config, then render to screen
function renderCustomizedConfig(newConfig) {
const config = { theme: "light" };
const moreConfig = isValidJSON(newConfig)
? JSON.parse(newConfig)
: isValidJSON(localStorage.getItem("storedConfigInput"))
? JSON.parse(localStorage.getItem("storedConfigInput"))
: {};
merge(config, moreConfig);
const configResult = `Style result: ${JSON.stringify(
config,
null,
2
)}`;
document.getElementById("configResult").textContent = configResult;
}
// Logic sent when "Submit Config" is pressed, including:
// 1. Get the user's input content
// 2. Render the latest custom style result
// 3. Store the custom style result in localStorage
function applyCustomizedConfig() {
const configInput = document.getElementById("configInput").value;
renderCustomizedConfig(configInput);
window.localStorage.setItem(
"storedConfigInput",
JSON.parse(JSON.stringify(configInput))
);
}
// Initialization logic
document.addEventListener("DOMContentLoaded", function () {
renderCustomizedConfig(); // Initialize rendering of custom style
renderDeleteButton(); // Initialize display of delete button
getUserAdminData(); // Trigger API call to get user admin data
document
.getElementById("applyButton")
.addEventListener("click", applyCustomizedConfig);
});
</script>
</body>
......omitted
Now for the answer.
First, the conclusion: the attacker will find that the content to pollute is Object.prototype.isAdmin, and the pollution method is to input { "__proto__": { "isAdmin": true } } in the input field and submit. Then, after pressing the page refresh button to render the page again, it causes the user admin "delete configuration button" to be displayed!
You can see the test screen below:
While the conclusion is simple, finding this conclusion from scratch requires a certain thought process and context. Let's go through the thought process:
First, recall that we've verified that the merge function has an issue and can be used to pollute the Object Prototype Chain. That is, we can input { "__proto__": { "key": "value" } } in the input field, causing Object.prototype.key = 'value'.
Next, let's think about the goal. The goal is to "make functionality that's only available to user admins appear." Reading the code above, we find that when the isAdmin of the user object is true, it will display functionality that only admins can see, which is the "delete configuration button."
function renderDeleteButton() {
const deleteButton = document.getElementById("deleteButton");
// user.isAdmin being true will display the "delete configuration button"
deleteButton.style.display = user.isAdmin ? "inline-block" : "none";
}
If we look at the source of the user variable, we find that it's const user = {}, meaning it's an empty object at initialization, with no isAdmin key! So when is user.isAdmin = true or user.isAdmin = false set? It has to wait until the simulated API getUserAdminData returns to set it.
But! After examining the detailed API call content, we further discover that when an API call error occurs, user.isAdmin = xxx is not triggered, and user remains an empty object. This means that if we can somehow make the API call fail, user will remain in a state without isAdmin. In this state, once user.isAdmin is called, it will trigger the Prototype Chain mechanism, and the final value found will be the value of Object.prototype.isAdmin, i.e., user.isAdmin = Object.prototype.isAdmin.
To make this exercise simple, the simulated API call always fails, so we can understand that user.isAdmin = Object.prototype.isAdmin is true.
const user = {};
// Simulate a getUserAdmin API request, but with a failed scenario
function sendUserAdminApiRequest() {
return new Promise((resolve, reject) => {
setTimeout(() => {
reject(new Error("API request failed"));
}, 2000);
});
}
// Make an API call to retrieve user admin data
function getUserAdminData() {
sendUserAdminApiRequest()
.then((response) => {
user.isAdmin = response;
renderDeleteButton();
})
.catch((error) => {
console.error("API request failed:", error.message);
});
}
Alright, now we just need to pollute Object.prototype.isAdmin = true to achieve our goal. So can we directly execute Object.prototype.isAdmin = true in the developer tools to make the "delete configuration button" appear? After trying, we find we can't. Even though Object.prototype.isAdmin = true would indeed pollute user.isAdmin, the rendering of the "delete configuration button" only happens when the renderDeleteButton function runs at the beginning of the page load. Changing user.isAdmin after renderDeleteButton has run is meaningless because it won't re-render. And if you try to refresh the page to make it re-render, it doesn't work either, because once you refresh, Object.prototype will be reset.
If that's the case, let's look at the rendering logic. After reading, we'll find that renderCustomizedConfig executes before renderDeleteButton, so we can see if there's a way to pollute the Prototype Chain in renderCustomizedConfig.
After reading renderCustomizedConfig, we discover that it retrieves the previous customized config result from localStorage, and through the problematic merge function, combines the default config with the customized config. This way, we just need to figure out how to store { "__proto__": { "isAdmin": true } } in localStorage, which would trigger config["__proto__"]["isAdmin"] = true, thereby polluting the Prototype Chain and achieving our goal.
function renderCustomizedConfig(newConfig) {
const config = { theme: "light" };
const moreConfig = isValidJSON(newConfig)
? JSON.parse(newConfig)
: isValidJSON(localStorage.getItem("storedConfigInput"))
? JSON.parse(localStorage.getItem("storedConfigInput"))
: {};
merge(config, moreConfig);
const configResult = `Style result: ${JSON.stringify(
config,
null,
2
)}`;
document.getElementById("configResult").textContent = configResult;
}
The logic for storing customized config files in localStorage is in the applyCustomizedConfig function, which is triggered when the "submit configuration button" is pressed. Finally, the attacker just needs to input { "__proto__": { "isAdmin": true } } in the input field, and then press the refresh button again, causing Object.prototype.isAdmin = true to become true, thereby causing user.isAdmin to be true. After rendering is complete, the "delete configuration button" appears!
function applyCustomizedConfig() {
const configInput = document.getElementById("configInput").value;
renderCustomizedConfig(configInput);
window.localStorage.setItem(
"storedConfigInput",
JSON.parse(JSON.stringify(configInput))
);
}
If anything above is unclear, you can read it several times or try it yourself, and it will become clearer!
Of course, in the real world, permissions should be controlled and checked by the backend. Even if some hidden operations can be displayed, they can't be directly attacked. After all, if you just want to display an operation button, you can just modify the CSS. This is more like drilling a hole with the Prototype Chain. However, through this example, it's not hard to imagine that through the Prototype Chain method, certain judgment conditions can be changed, causing rendered content to change, leading to more serious attacks, such as rendering executable code, or sending things that shouldn't be sent to the backend (and the backend doesn't check), which could lead to unexpected consequences.
Finally, to summarize, if an attacker wants to use Prototype for attacks, they generally need:
- The attacker will try to find "ways to pollute the Prototype Chain," creating security vulnerabilities
- The attacker also needs to find "what content to pollute," and when the polluted content is combined with "other code," it can produce actual attacks
There's a specific term called Prototype Pollution Gadgets that specifically refers to those "originally normal and harmless, but when the Prototype is polluted, will lead to unexpected attacks" code fragments. I'm just mentioning it briefly. If you're interested, you can look it up or read "Beyond XSS."
Methods to Prevent Prototype Chain Pollution
Since we've discussed how the Prototype Chain can be polluted by attackers, let's look at ways to prevent such attacks.
1. Filter Out Keywords Like __proto__, prototype, etc.
Since attackers need to use keywords like __proto__, prototype, constructor in their input values to successfully pollute the Prototype Chain, we can simply filter out these keywords. You can use sanitize libraries like DOMPurify to handle this.
For functions like merge, you can filter out related keys like this:
function merge(target, source) {
for (let key in source) {
// Filter out "__proto__", "prototype", and "constructor"
if (key === "__proto__" || key === "prototype" || key === "constructor") {
continue;
}
if (typeof source[key] === "object" && source[key] !== null) {
target[key] = merge(target[key] || {}, source[key]);
} else {
target[key] = source[key];
}
}
return target;
}
Of course, in practice, developers usually don't write functions like merge themselves, but directly use libraries like lodash to handle it, so they don't need to reinvent the wheel. But if using third-party libraries, what should we pay attention to? The most important thing is that if there's a new version that patches security vulnerabilities, upgrade it quickly!
However, developers usually don't check for third-party library updates every day, so a response method is to include security detection jobs in the CICD process, using tools like Trivy security scanner to automatically scan libraries for issues during each deployment.
2. Treat Keywords Like __proto__, prototype as Pure Properties
While we can increase security by "ignoring" keywords like __proto__ by modifying merge as described above, what should we do if we need to use keys like __proto__?
There's a JS method called Object.defineProperty that can define Object Properties. Using this, we can treat keywords like __proto__ as ordinary object property keys, thereby avoiding pollution of prototype objects. The concept in code is as follows:
// From lodash v5 source code
function baseAssignValue(object, key, value) {
// If the key equals '__proto__', define it as a pure Property of the Object
if (key === '__proto__') {
Object.defineProperty(object, key, {
'configurable': true,
'enumerable': true,
'value': value,
'writable': true
})
} else {
object[key] = value
}
}
At first glance, since the settings in Object.defineProperty are 'configurable': true, 'enumerable': true, 'value': value, 'writable': true, it seems no different from object.__proto__, as both can be assigned values and modified. However, the difference is that object.__proto__ modifies Object.prototype, while Object.defineProperty(object, key, {'value': value, ...} does not modify Object.prototype, thereby avoiding pollution of the Prototype Chain.
For the merge in the demo case described above, you just need to determine when key is __proto__, prototype..., and use the Object.defineProperty method for assignment, which would be relatively safer.
3. Create Objects Without a Prototype Chain Using Object.create(null)
For critical objects that absolutely cannot be polluted, you might consider using Object.create(null) to create them. Objects created this way do not inherit properties from Object.prototype:
const obj = Object.create(null);
console.log(obj.toString); // undefined
console.log(obj.hasOwnProperty); // undefined
For the demo case, you just need to change the way the user object is created to use Object.create to avoid pollution.
Besides this, you can also use new Map to create object-like user objects, which do not inherit from the Prototype Chain, which is another way to prevent user from being polluted.
4. Prevent Adding Properties to Object.prototype Using Object.freeze(Object.prototype) or Object.seal(Object.prototype)
There are two ways to directly prevent objects from adding properties:
- Object.freeze: Completely freezes an object, preventing the addition, modification, or deletion of any properties, and also preventing changes to property settings (such as writable, configurable).
- Object.seal: Seals an object, preventing the addition or deletion of properties, but still allowing the modification of existing property values. This provides more flexibility than freeze.
// Use "Object.freeze" to freeze Object.prototype
Object.freeze(Object.prototype);
// Attempting to modify properties of Object.prototype fails
Object.freeze(Object.prototype);
Object.prototype.toString = 'string';
console.log(Object.prototype.toString); // f toString()
// Attempting to add properties to Object.prototype also fails
Object.prototype.newProp = 'new';
console.log(Object.prototype.newProp); // undefined
// Use "Object.seal" to seal Object.prototype
Object.seal(Object.prototype);
// Existing properties can be modified, which will succeed
Object.prototype.toString = "string";
console.log(Object.prototype.toString); // string
// But adding new properties or deleting properties will fail
Object.prototype.newProp = 'new';
console.log(Object.prototype.newProp); // undefined
But directly locking down Object.prototype (or Array.prototype, etc.) is not the best approach, because many third-party libraries use the prototype feature to provide polyfill functionality, thus allowing the same method to support multiple browser or device environments.
So unless it's a very specific scenario, such as knowing for certain that no third parties will be used and security needs to be maximized, would this approach be considered. Of course, relatively speaking, Object.seal is milder.
Extended Methods
The methods described above all attempt to directly prevent the Prototype Chain from being polluted. Among them, the best practice in real-world applications is probably the second method used by lodash: "Treat keywords like __proto__, prototype as Pure Properties." Of course, this still depends on the specific scenarios of your project.
However, polluting prototypes alone usually has no meaning. In practice, it would be combined with further techniques, such as changing certain conditions due to Prototype Pollution, which further allows certain scripts to be inserted and executed, etc. So if you prevent scripts from being executed, you can also block the entire attack.
This involves many extended security measures, such as CSP (Content Security Policy) settings, whether Sanitization is implemented, etc., which are beyond the scope of this article. If you're interested, as mentioned above, you can research on your own or read "Beyond XSS."
Summary and Practical Takeaways
From the definition of Prototype, to Prototypal Inheritance, Prototype Chain, and Prototype Pollution, we've broadly covered the concepts and simple applications of JS prototypes. Let's quickly review a few questions:
What is a Prototype
In JavaScript, a Prototype is an object used for property sharing between Object data.
Specifically, every Object data has an internal property [[Prototype]] for a prototype object. If you want to access that prototype object in code, you can do so through obj.__proto__ or Object.getPrototypeOf(obj).
The content of the prototype object comes from the prototype property value in the object's constructor, for example:
// constructor Dog
function Dog(name){
this.name = name
}
// Use prototype to make new Dog object instances bark
Dog.prototype.bark = function(voice) {
console.log(voice)
}
const dogA = new Dog('肚子')
const dogB = new Dog('吐司')
// The source of bark is constructor.prototype
console.log(dogA.bark === dogB.bark) // true
console.log(dogA.bark === dogA.__proto__.bark) // true
console.log(dogA.__proto__.bark === Dog.prototype.bark) // true
What is a Prototype Chain
This is a conceptual description of the process of looking up object properties.
In Javascript, when calling an Object Data property, if that property is not found, it will look in its [[Prototype]] object. If found, it returns the value corresponding to the property; if not found, it will look in the higher-level [[Prototype]] object of the [[Prototype]] object. This logic is repeated until the property is found and its corresponding value is returned, or until the Prototype is null, meaning there is no higher-level Prototype content, at which point it returns undefined.
This process is the Prototype Chain.
What is Prototype Pollution
Prototype Pollution is a security vulnerability where attackers can exploit it to modify JavaScript's prototype objects (usually Object.prototype). Such pollution can cause the return values of object property calls to change, which, combined with other code (Prototype Pollution Gadgets), can further lead to more serious security issues.
So After Understanding These, What Can We Do?
I believe that after understanding, in practice, we can do:
1. Avoid Modifying the Native JS Prototype Chain
Because modifying the native JS Prototype Chain affects too broad a range, it can lead to many unpredictable problems.
It's best to use automation like ESLint rules to restrict developers from making random changes, and to run ESLint checks during the CICD process.
Additionally, in the Code Review process, be sensitive to this. Once you see characters like __proto__, prototype, think about the Prototype Chain, and better yet, when dealing with important objects, think a bit about whether there might be issues, and whether you need to use methods like Object.create or Map to handle important data.
2. Consider Using Prototypal Inheritance If Methods Need to Be Available to All Object Data
The advantage of Prototypal Inheritance is that it allows all inherited Objects to have the same property methods, and the memory addresses are the same, which not only allows for common maintenance but also reduces memory usage.
However, if it's just in a single project, I personally tend to simply declare an independent shared function, then import it into the files that need it, not necessarily needing to use the Prototype feature.
But if it's in a library provided for others to use, it might be more worth considering whether there are suitable scenarios to use this feature.
3. Don't Trust User Input
Anywhere related to user input, including URLs, input fields, etc., be careful about inputting keywords like __proto__, prototype, which might lead to Prototype Pollution if not handled properly when mixing data with objects.
However, many third-party libraries already handle this, so you can just use them directly. For example, lodash's merge already includes filtering.
4. Regularly Perform Security Checks
Even if using third-party libraries, there might be security vulnerabilities that lead to prototype pollution, so try to perform security checks during CICD, which can automatically remind you to upgrade third-party library versions, thereby avoiding security vulnerabilities as much as possible.
I hope that after reading this article, you'll have a clearer understanding of Prototype-related concepts. Personally, the most new knowledge I gained during the writing of this article was about Prototype Pollution security-related issues, as it's a concept I only seriously understood after recently reading books. After actually understanding it, I found it quite interesting, and I took this opportunity to fill in this gap in my knowledge!