Understanding JavaScript Execution Flow: The Event Loop Explained Through Code Examples
Introduction
Recently, I returned to AppWorks School as a mock interviewer and while preparing asynchronous questions, I realized I had forgotten some concepts about the Event Loop, especially regarding the execution order and process of Tasks (Macrotasks) and Microtasks. Since I hadn't previously written down this knowledge, I'm using this article to organize my understanding of the Event Loop and related concepts.
After reading this article, you should be able to answer the following questions:
- Why can
JavaScriptexecute tasks asynchronously? - What is the
Event Loop? - What are
Tasks (Macrotasks)andMicrotasks? - How does the
Event Loopwork? - How can we prevent lag caused by high-cost
Eventhandling?
In the final section, I'll provide several examples mixing setTimeout and Promise to test your understanding of program execution flow (these are also common interview questions).
Let's start by understanding the first concept: Call Stack.
The Call Stack: Executing One Task at a Time
JavaScript is a single-threaded language, meaning it can only execute one task at a time. We can understand this by looking at how the Call Stack works.
The Call Stack, also known as the Execution Stack, is a space that records the current execution state of a program. When JavaScript runs, it places tasks to be executed at the top of the Call Stack, and only removes them after execution is complete.
Let's understand the Call Stack through the following code:
function fn1() {
console.log('fn1');
}
function fn2() {
fn1();
console.log('fn2');
}
function fn3() {
fn2();
console.log('fn3');
}
fn3();
// Output order: fn1 -> fn2 -> fn3
The code execution steps are as follows:
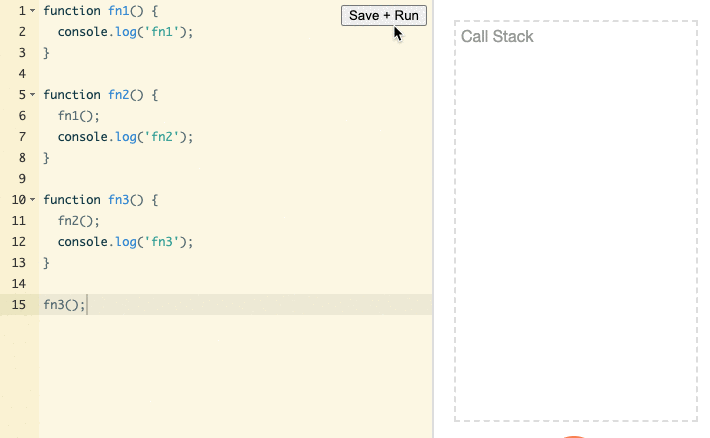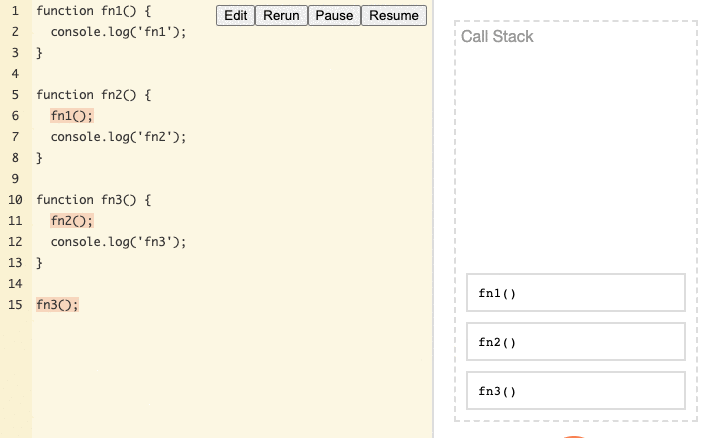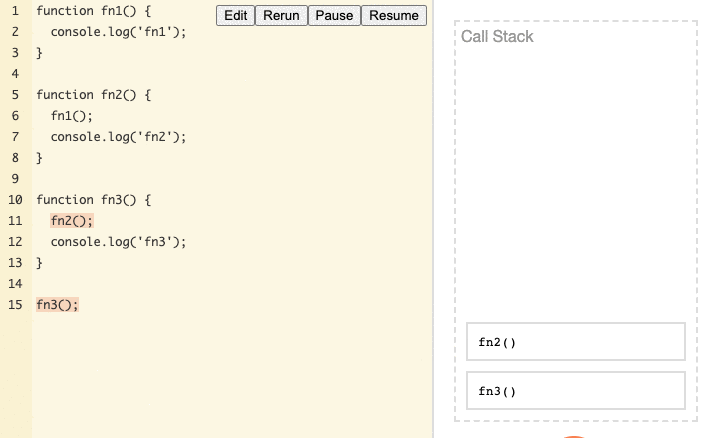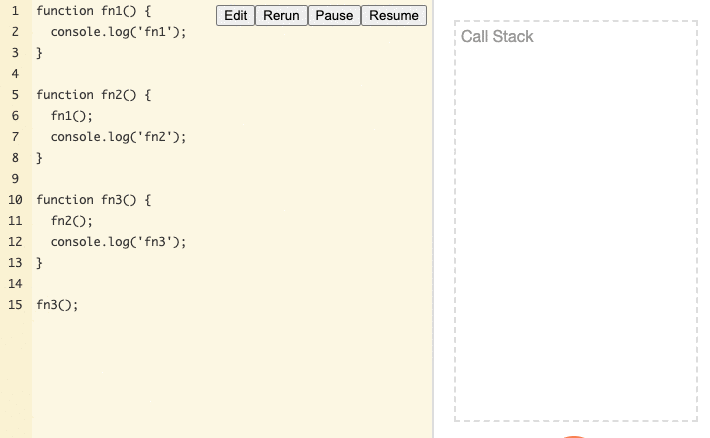
fn3is called and moved to the top of the Stack for execution.- While executing
fn3, we encounter and callfn2, which is then moved to the top of the Stack for execution. - While executing
fn2, we encounter and callfn1, which is moved to the top of the Stack for execution. - We execute
fn1, print'fn1', and afterfn1is complete, it's removed from the Stack. - We execute the function now at the top,
fn2, print'fn2', and afterfn2is complete, it's removed from the Stack. - We execute the function now at the top,
fn3, print'fn3', and afterfn3is complete, it's removed from the Stack.
Note: In reality, the first step in the Call Stack is "executing the global environment (Global execution context)", after which the execution environments of each function begin to stack.
Using the loupe tool, we can more concretely and visually understand the entire operation:
 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
We can see that when execution reaches a certain line, that task is added to the Call Stack.
If it's a simple program (e.g., console.log), it will be executed immediately and removed from the Call Stack.
However, if we're executing a function, it needs to be completely executed (returning something or undefined) before it's removed from the Call Stack.
Interestingly, when the first function calls a second function, the "more recently called" second function is executed first. After the second function completes, execution returns to the first function to continue. For example, fn1 is executed last but completes first, while fn3 is executed first but completes last.
From the GIF of program operation, we can see that functions are stacked, and the function at the top will be the first to complete execution and be removed from the Call Stack.
From this Call Stack example, we can observe two things:
- Function execution order follows the "Last In, First Out" (LIFO) pattern.
- Only the task at the very top of the
Call Stackcan be executed at any given time.
So we can imagine: in a single-threaded environment where only one task can be executed at a time, if a task takes an extremely long time, such as a network request (XMLHttpRequest) or setTimeout(fn, 3000), it will block all subsequent tasks.
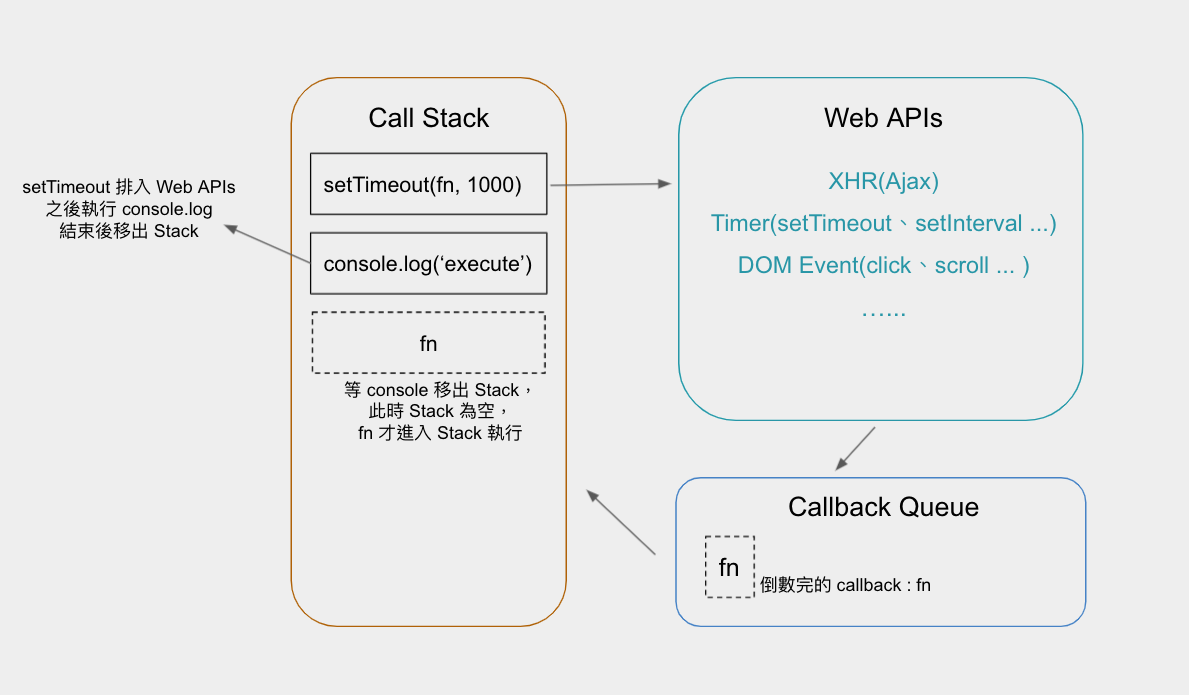
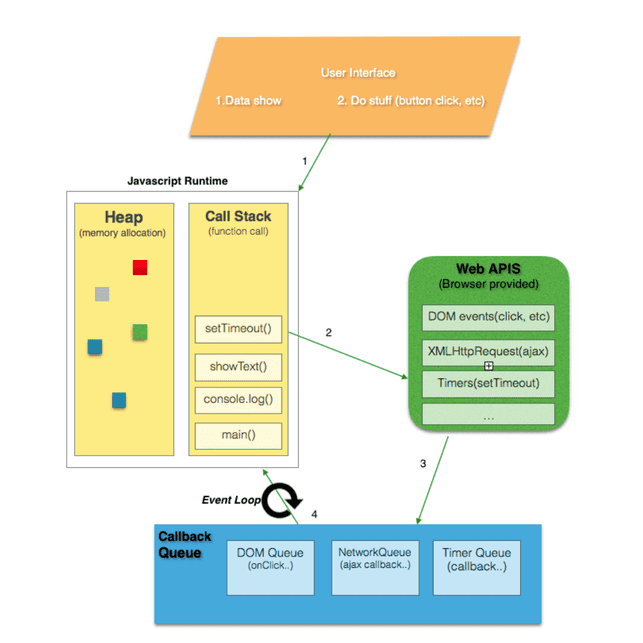
Web APIs: Making Simultaneous Execution of Multiple Tasks Possible
Since JavaScript can only do one task at a time, we need "another mechanism" to help resolve the blocking problem caused by long-running tasks.
Where does this other mechanism come from? It comes from the JavaScript "execution environment," such as Browser or Node.js.
In the Browser execution environment, Web APIs are provided to help handle time-consuming tasks like XMLHttpRequest (XHR), setTimeout, setInterval, etc. When these items are encountered, they are first handed over to the Browser for processing, which prevents blocking the original thread, thereby enabling multiple tasks to be executed simultaneously, rather than just one at a time.
When the Web APIs finish processing their assigned logic, they return a Callback task to be executed. This Callback task isn't placed directly back into the Call Stack; instead, it's first queued in the Callback Queue. When the Call Stack is empty, only then are tasks from the Callback Queue moved into the Call Stack for execution.
Let's understand the entire process through a setTimeout example:
function fn1() {
console.log('fn1');
}
function fn2() {
console.log('fn2');
}
function fn3() {
console.log('fn3');
setTimeout(fn1, 1000);
// 1. When setTimeout executes, the countdown logic of 1s is handed to Web API.
// 2. After the 1s countdown is complete, the fn1 Callback is moved to the Queue, waiting for the Stack to clear.
// 3. After the Stack clears, the fn1 Callback is moved to the Stack for execution.
fn2();
}
fn3();
// Output order: fn3 -> fn2 -> fn1
 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
The execution steps are as follows:
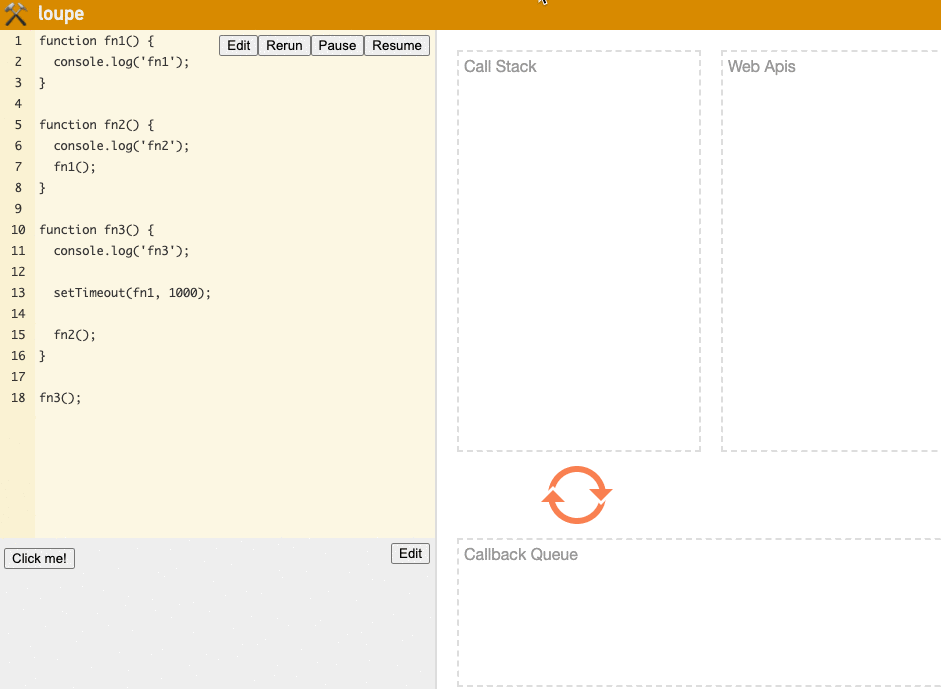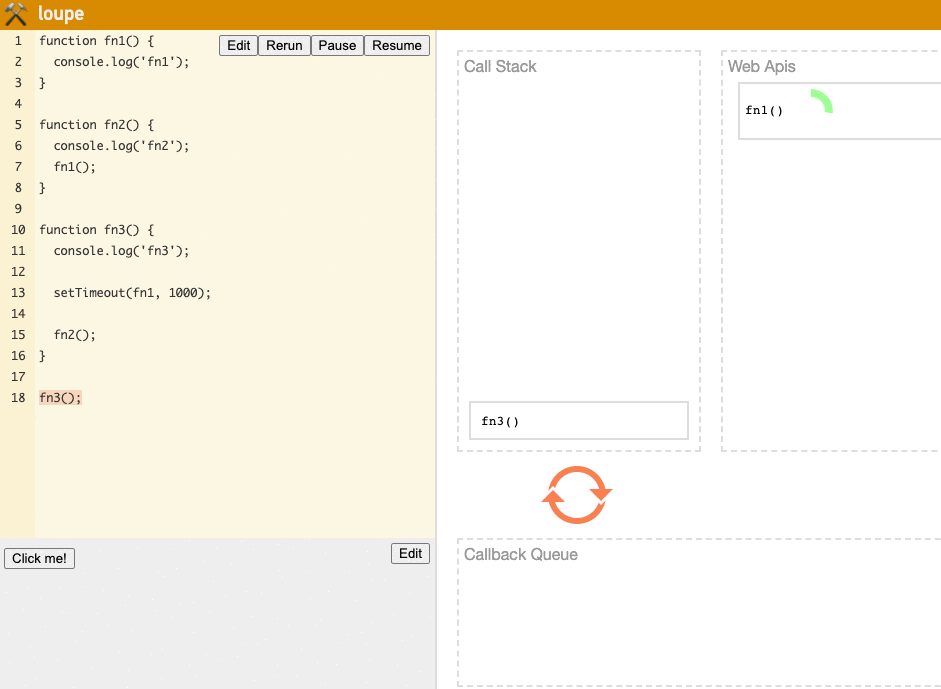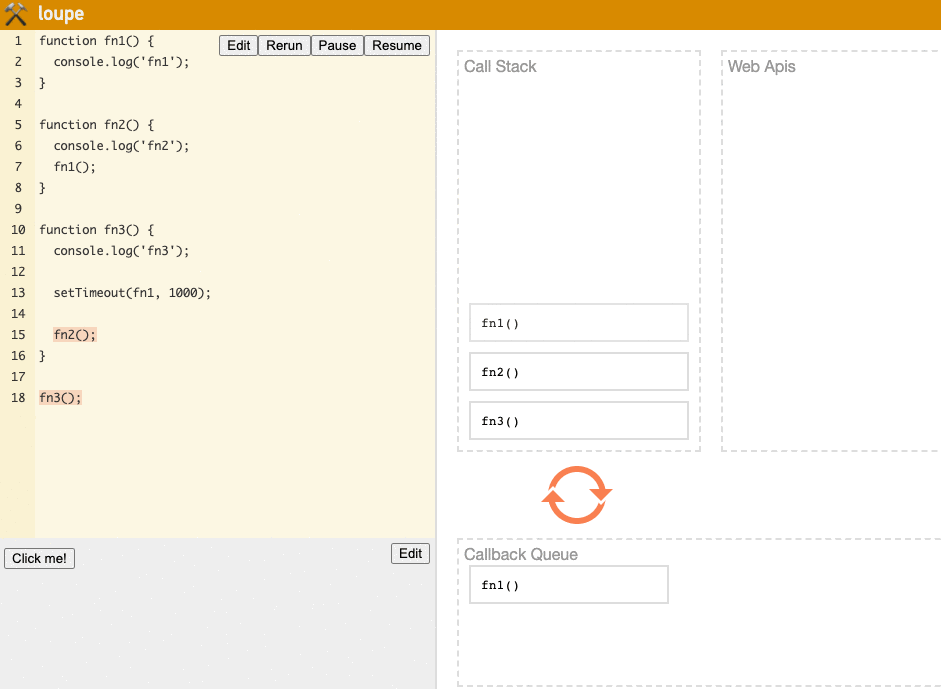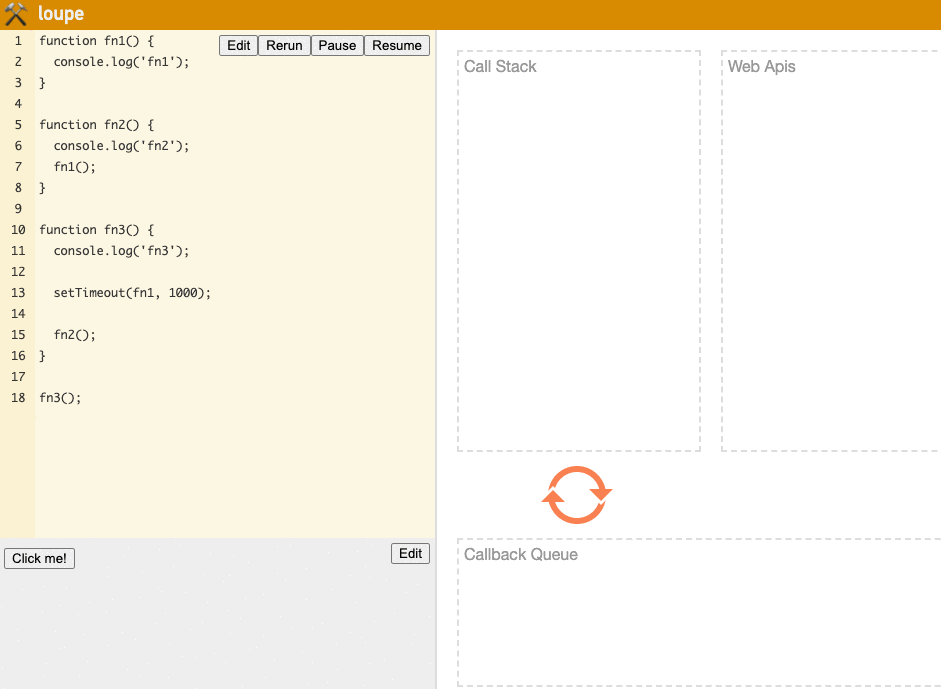
fn3is called and moved to the Stack for execution.'fn3'is printed, then we reachsetTimeout(fn1, 1000).fn1is passed to the Web API for a 1s countdown, after which fn1 moves to the Queue to wait. (This doesn't block the Stack)fn3continues executing, encountersfn2, andfn2is moved to the top of the Stack for execution.'fn2'is printed,fn2completes execution, and is removed from the Stack.- We execute the function now at the top,
fn3, print'fn3', and afterfn3is complete, it's removed from the Stack. - The
fn1stored in the Queue is moved to the Stack for execution. 'fn1'is printed,fn1completes execution, and is removed from the Stack.
From the GIF of program operation, we can clearly see two key points:
- The 1s countdown process of
setTimeout(fn1, 1000)doesn't block the execution of other tasks in theCall Stack, because it's handled byWeb APIs, thus achieving the running of multiple tasks. setTimeout(fn1, 1000)does not guarantee thatfn1will execute exactly after 1s. After 1s,fn1is only queued in theCallback Queueto wait until theCall Stackis empty, at which pointfn1will be moved into the Stack for execution. Therefore, we can only say "it guarantees thatfn1will execute at least 1s later."
At this point, we can understand why JavaScript is single-threaded but can still execute multiple tasks simultaneously.
Exploring the Event Loop: What Exactly Is It?
The content described above already includes the concept of the Event Loop.
In a nutshell, the
Event Loopis the asynchronous execution cycle mechanism for event tasks between theCall StackandCallback Queue.
This is just an overview, meaning there are still details about Tasks (Macrotasks) and Microtasks that haven't been explained, which will be covered in more detail later.
It's important to emphasize that the JavaScript language itself doesn't have an Event Loop; rather, it works with an "execution environment" to establish an Event Loop mechanism. Environments like Browser or Node.js each have their own Event Loop mechanism.
Let's summarize the main points so far:
- The
Event Loopis a mechanism for handling the execution order of asynchronous tasks. - The
Event Loopexists in JS execution environments, such as theBrowser Event LooporNode Event Loop. - The
Browser Event Loopis associated with the interaction between theCall Stack,Web APIs, andCallback Queue.- When asynchronous tasks like
setTimeoutorXHRare encountered, they are handled byWeb APIs, not blocking theCall Stack. - After the
Web APIsfinish handling asynchronous logic, they throw the Callback task back to theCallback Queueto wait. - When the
Call Stackis empty, it receives and executes the Callback task.
- When asynchronous tasks like
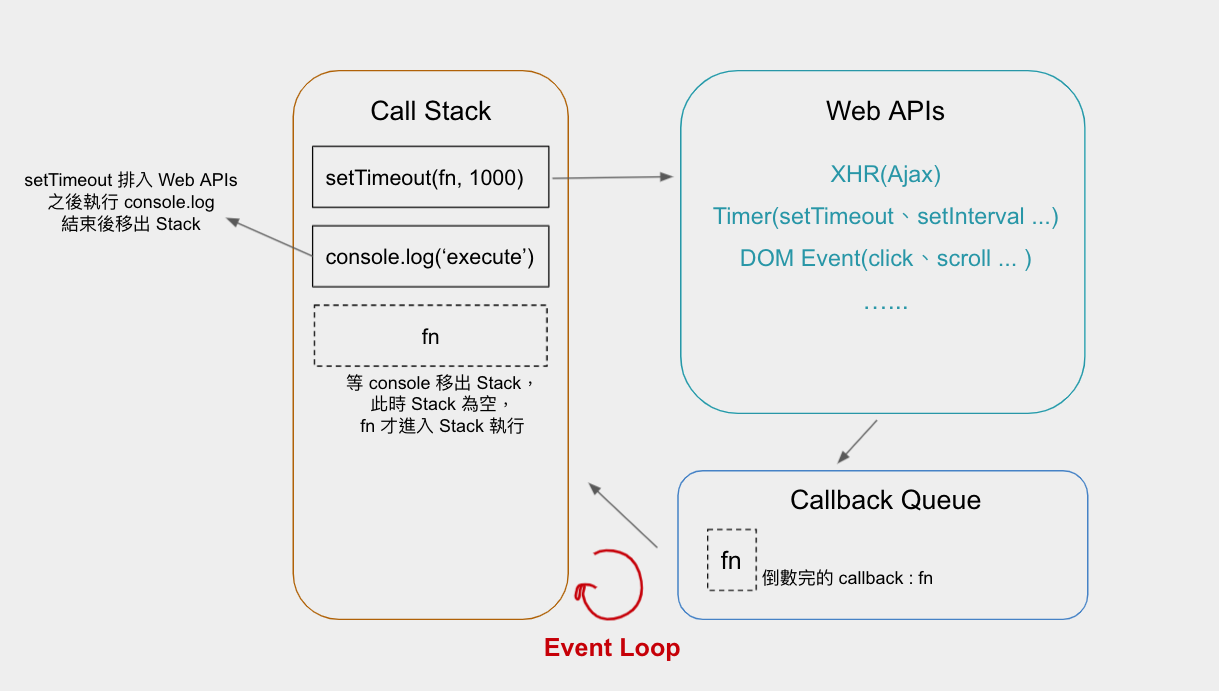
Here's a classic full picture of the Browser Event Loop, which should help you understand its meaning:
There are two special points worth noting:
- In the
Callback Queue, there are different types ofQueues, such asTimer Queue,Network Queue, etc. So we can say that in theEvent Loop, there may be multiple types ofQueuesat the same time. - Web APIs don't just help with time-consuming tasks; they also handle many other tasks like
DOM events (click, scroll...). So when we encounter events likeonClick, they also enter theWeb API+Callback Queue+Call Stackcycle.
Regarding the second point, let's demonstrate it directly using loupe:
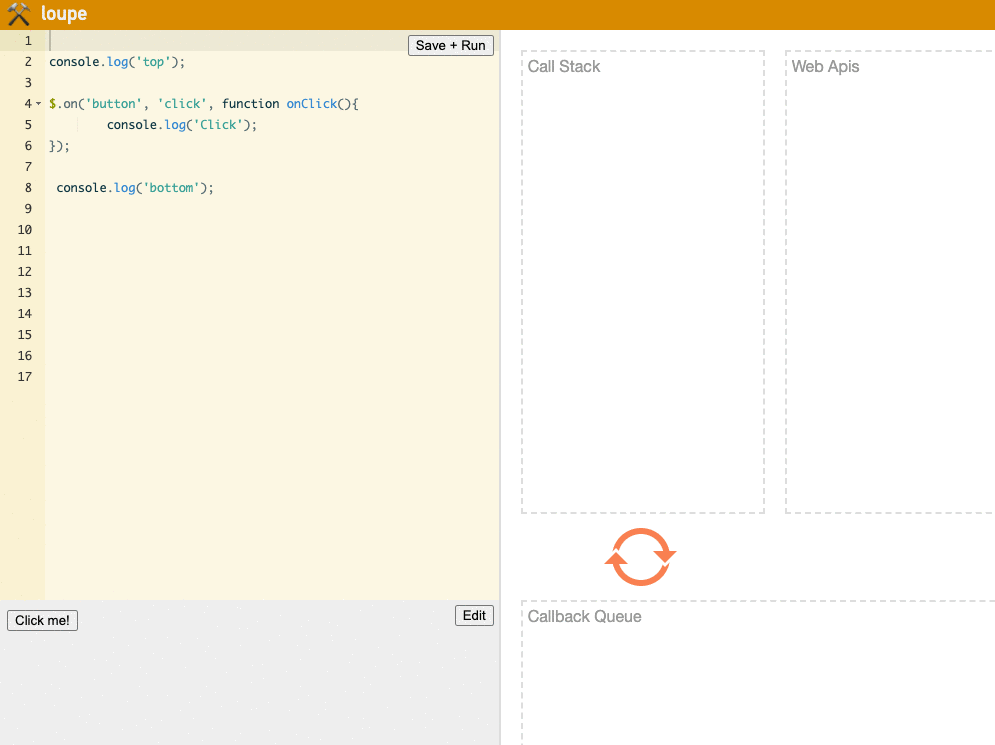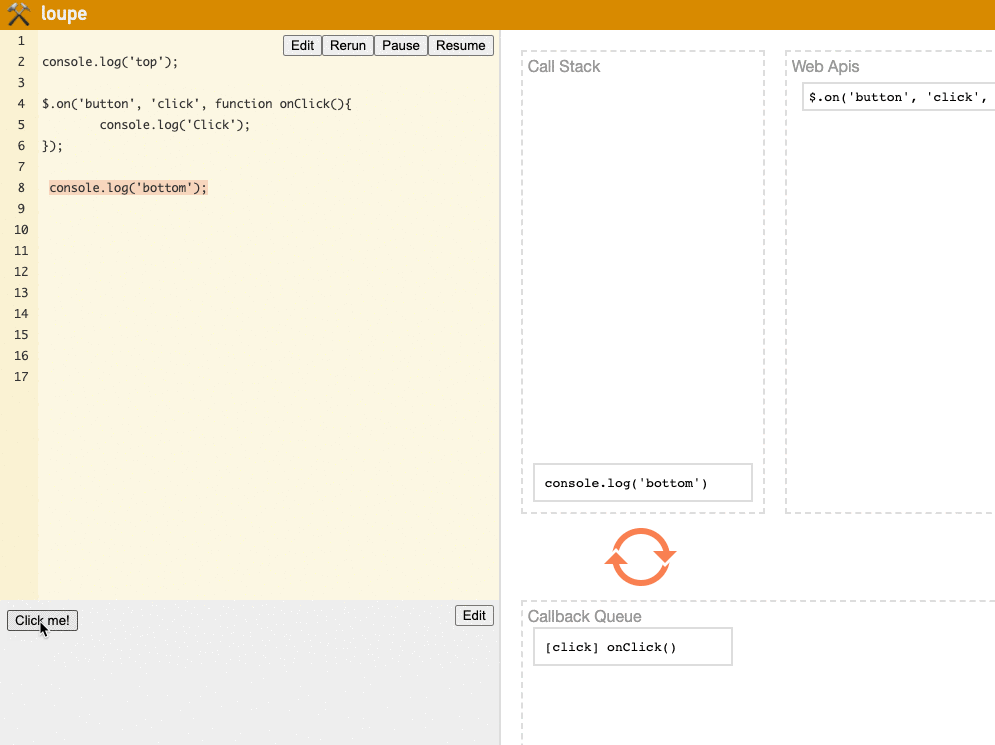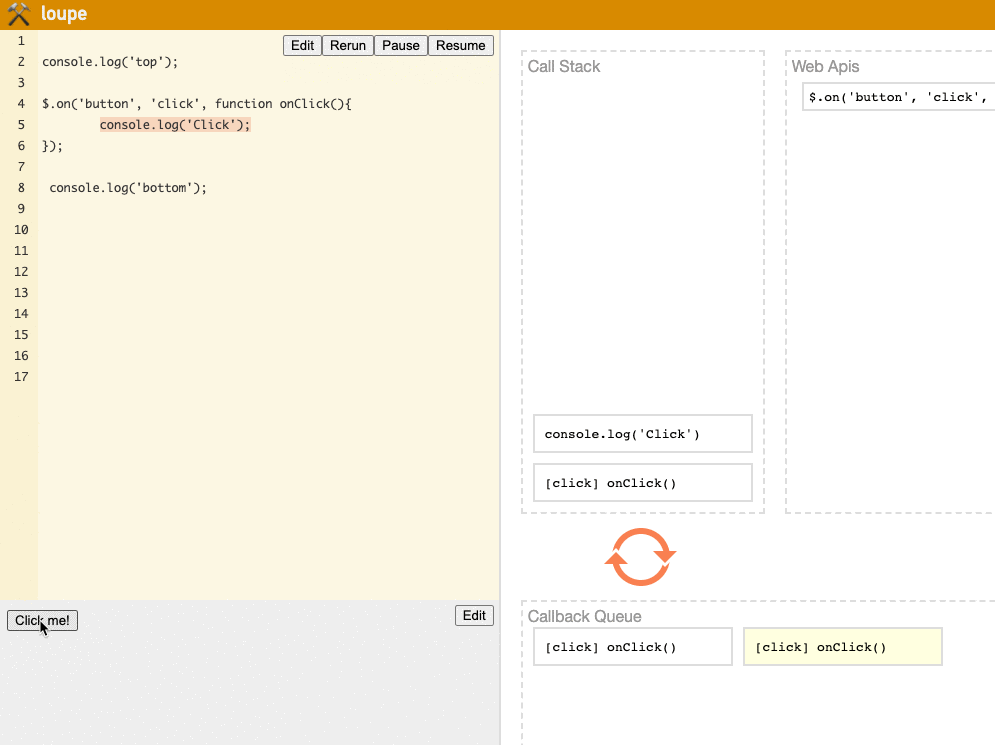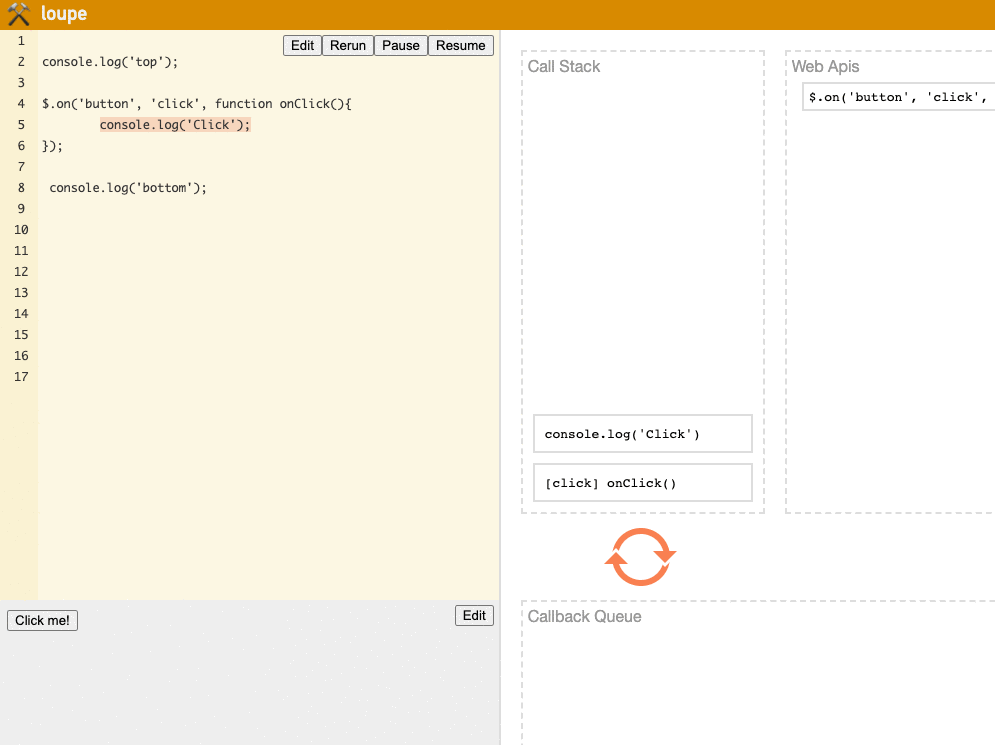 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
We can see that each time the Click button is clicked, the event is first handed to the Web API, then enters the Callback Queue and Call Stack, running the Event Loop mechanism.
Deep Dive into the Event Loop: Tasks (Macrotasks) and Microtasks
In the operation of the Event Loop, event tasks actually have two types: Tasks (Macrotasks) and Microtasks.
From this article on MDN, we can learn the following definitions:
Tasks (Macrotasks)
A task is any JavaScript code which is scheduled to be run by the standard mechanisms such as initially starting to run a program, an event callback being run, or an interval or timeout being fired. These all get scheduled on the task queue.
These include but are not limited to:
- Parsing HTML
- Executing JavaScript mainline and scripts
- URL changes
- setTimeout, setInterval => callback events (the callback fn parameter passed in)
- Publishing Event events => callback events (onClick, onScroll, etc.)
- Obtaining network resources => callback events (callback fn after XHR)
Note: Task is actually what is commonly known as Macrotask. From this point on, I'll also use Task to refer to macrotasks.
When these Tasks are triggered, they are queued in specific Task Queues. For example, callbacks from setTimeout and setInterval are queued in the Timer Queue, while callbacks from Event events are queued in the DOM Event Queue.
These different types of Queues allow the event loop to adjust execution priorities based on different task types. For instance, tasks emphasizing immediate response, such as handling user input, might be given higher priority. However, different browsers implement this differently, so it can be said that the browser determines which type will be executed first.
This means that for different types of macrotasks, their processing priority does not guarantee that whoever triggers first will execute first; this still depends on how the browser implements it.
The Callback Queue mentioned earlier actually refers to the Task Queue, as shown in the concept diagram below:
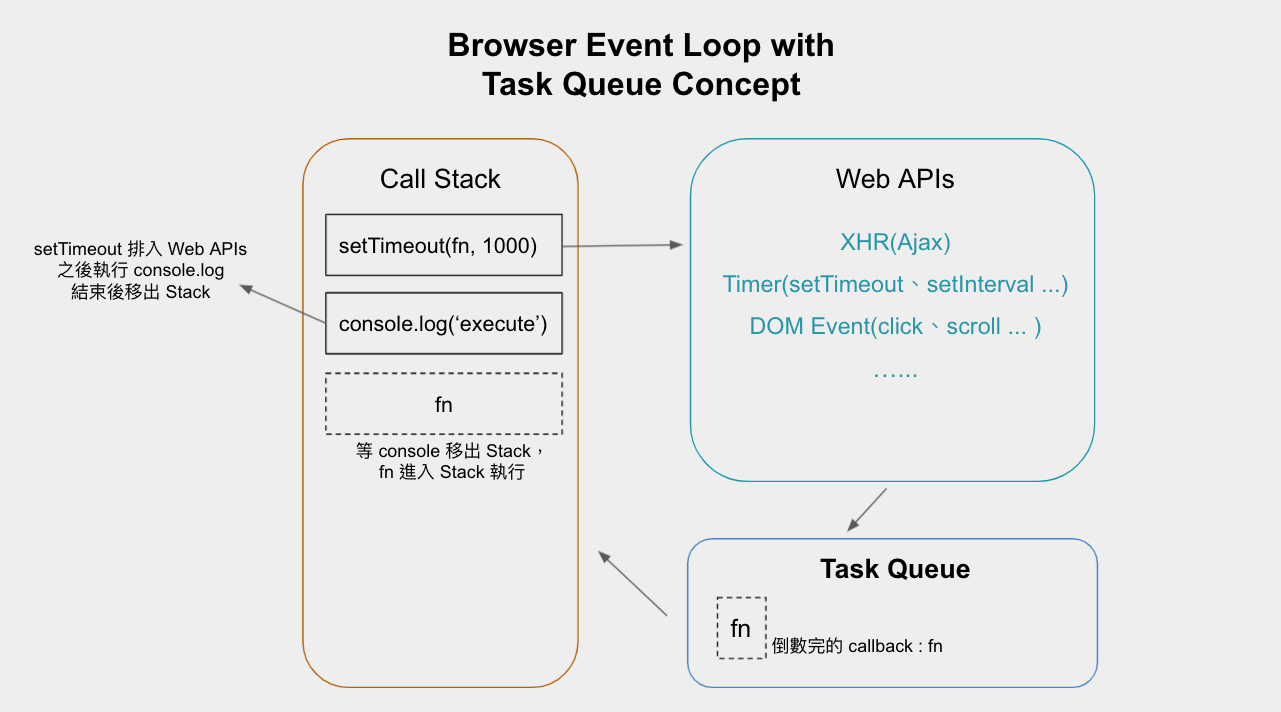
Microtasks
A microtask is a short function which is executed after the function or program which created it exits and only if the JavaScript execution stack is empty, but before returning control to the event loop being used by the user agent to drive the script's execution environment.
As the name suggests, microtasks are smaller tasks whose asynchronous callbacks are not placed in the Task Queue but are handled by the Microtask Queue. These include but are not limited to:
- Promise then callbacks (executor is synchronous)
- MutationObserver callbacks
Let's focus on Promise, which is most commonly used in implementation.
Microtasks typically don't consume as much performance as Tasks and are executed as early as possible. They execute after a Task completes and the Call Stack is empty.
Remember earlier I mentioned there were some details about the Event Loop that weren't covered?
Yes, that's the concept of Microtasks. After adding them, the concept diagram looks like this:
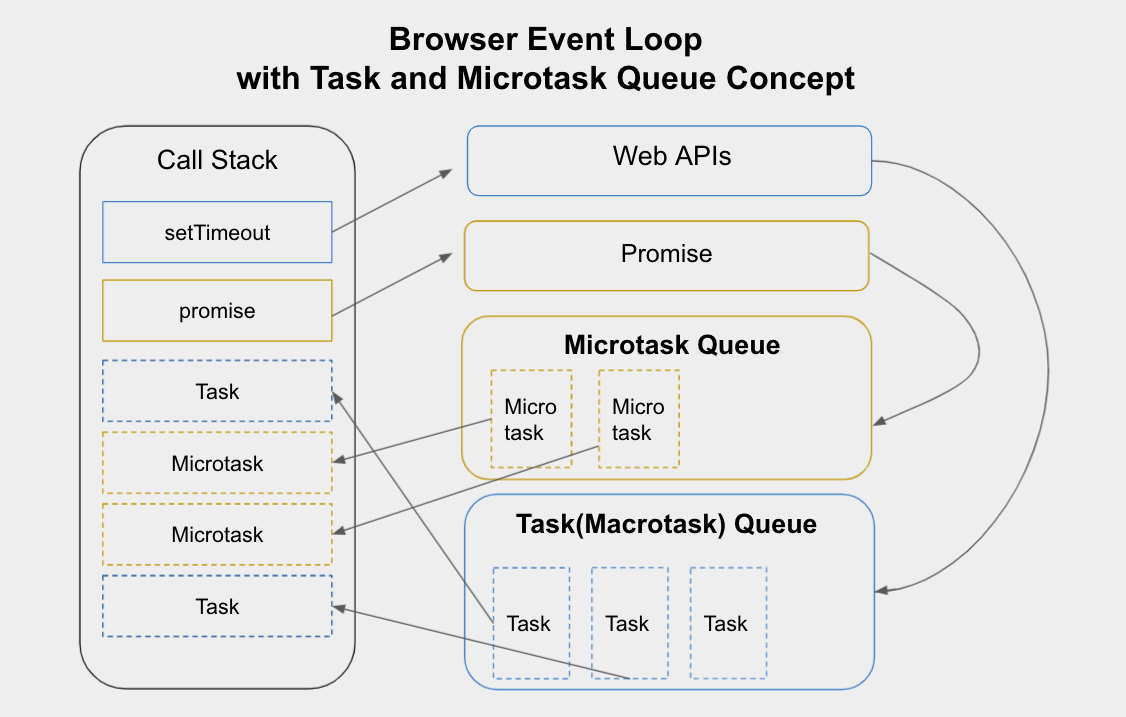
At this point, we have a basic understanding of Tasks and Microtasks, so let's now explore in detail how these two operate in the operation cycle flow of the Event Loop.
Operation Flow of Tasks (Macrotasks) and Microtasks
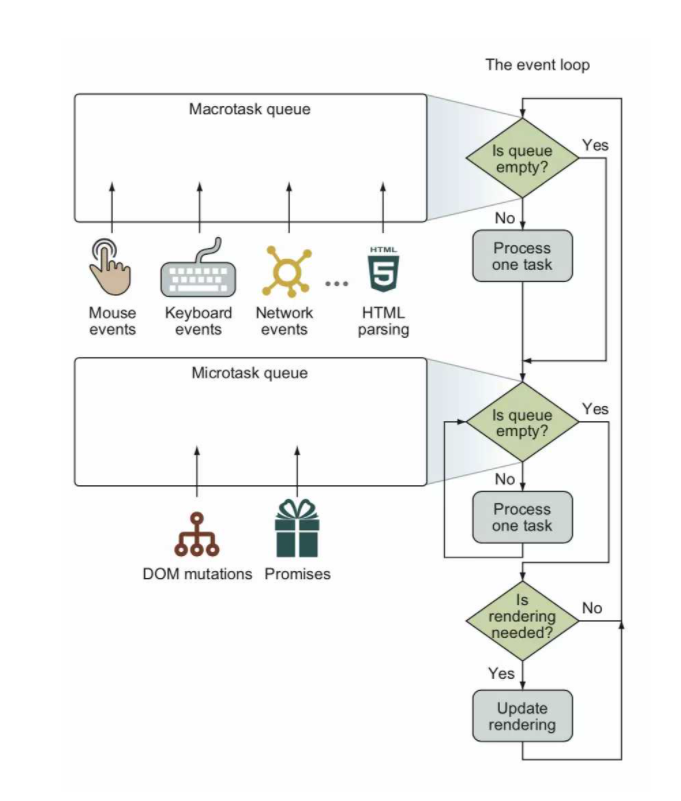
This diagram is a classic representation of how Tasks and Microtasks operate in the Event Loop. Let's look at some key points:
- In one cycle, we first check if there are any
Tasksin theTask Queue. - If there is a
Task, we execute it; if not, we proceed directly to checking theMicrotask Queue. - After completing a
Task, we check if there are anyMicrotasksin theMicrotask Queue. - If there are
Microtasks, we execute them, and we only proceed to the nextrenderphase after completing allMicrotasksin theMicrotask Queue. - If rendering is needed, we render; if not, we don't execute. Then we return to step 1.
A crucial insight from this is:
In a single cycle, only one macrotask (Task) is processed, but all microtasks (Microtask) are processed.
We can understand this through the execution of the following program:
<script>
console.log('script start');
setTimeout(function () {
console.log('setTimeout callback');
}, 1000);
new Promise(function (resolve, reject) {
console.log('promise 1 resolve');
resolve();
}).then(function () {
console.log('promise 1 callback');
});
new Promise(function (resolve, reject) {
console.log('promise 2 resolve');
resolve();
}).then(function () {
console.log('promise 2 callback');
});
console.log('script end');
</script>
// What is the order of the output? => Think about it first, then the answer will be clear after understanding the operation flow.
- There's a
scriptTask, so thisTaskis executed, and thescriptstarts running. - We encounter
console.log('script start')and printscript start. - We encounter
setTimeout, which is asynchronously counted down by theWeb API, and after the countdown, it's thrown into theTask Queueto wait for execution. - We encounter
promise 1, first execute theexecutorsynchronously, and printpromise 1 resolve. - After
resolveis complete, we throw thepromise 1callback functioninto theMicrotask Queueto wait for execution. - We encounter
promise 2, first execute theexecutorsynchronously, and printpromise 2 resolve. - After
resolveis complete, we throw thepromise 2callback functioninto theMicrotask Queueto wait for execution. - We encounter
console.log('script end')and printscript end. - At this point, the
scriptTaskis complete, and we enter the phase of checking if there are pending items in theMicrotask Queue. - There are two callbacks in the
Microtask Queue:promise 1andpromise 2. Both are executed, printingpromise 1 callbackandpromise 2 callback. - At this point, there are no items in the
Microtask Queue, so we proceed to whether torender, and the screen might be updated. - One cycle is complete, and a new cycle begins from the start.
- We check the
Task Queueand find there's asetTimeoutcallback, which we execute, printingsetTimeout callback. - At this point, the
setTimeout callbackTaskis complete, and we enter the phase of checking if there are pending items in theMicrotask Queue. - There are no items in the
Microtask Queue, so we proceed to whether torender, and the screen might be updated. - We cycle again, find there are no more tasks, and end.
So the output will be:
-
First cycle
- script start
- promise 1 resolve
- promise 2 resolve
- script end
- promise 1 callback
- promise 2 callback
-
Second cycle
- setTimeout callback
Although the loupe website doesn't show the Microtask Queue, we can still visually observe the program's operation flow:
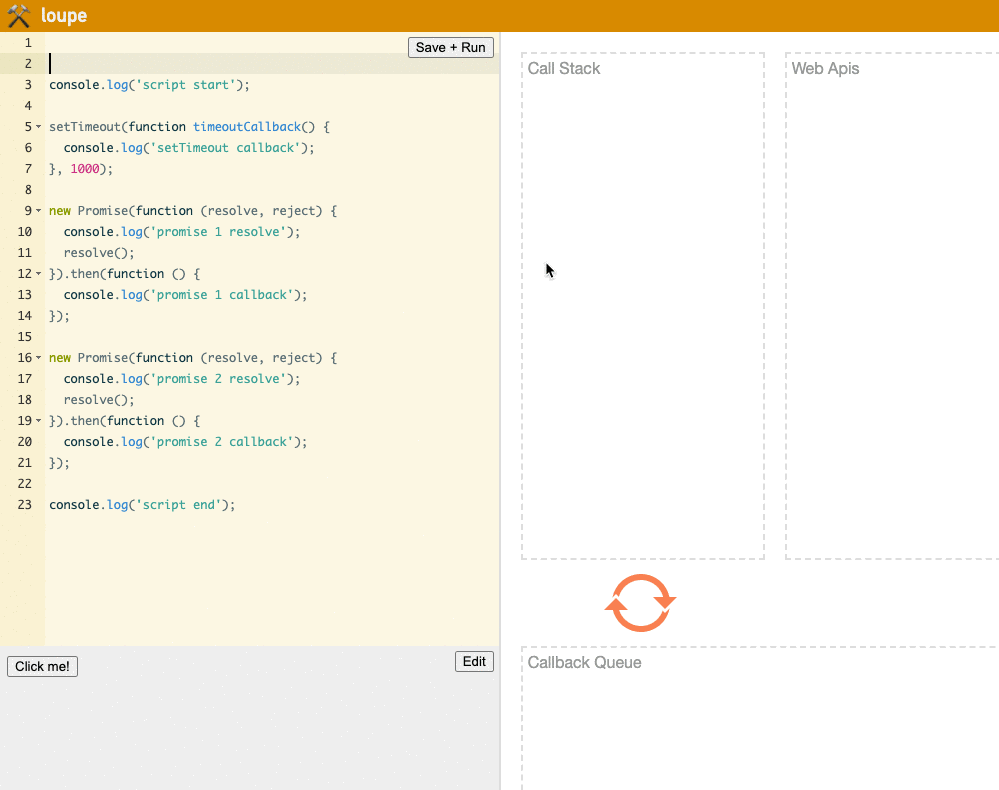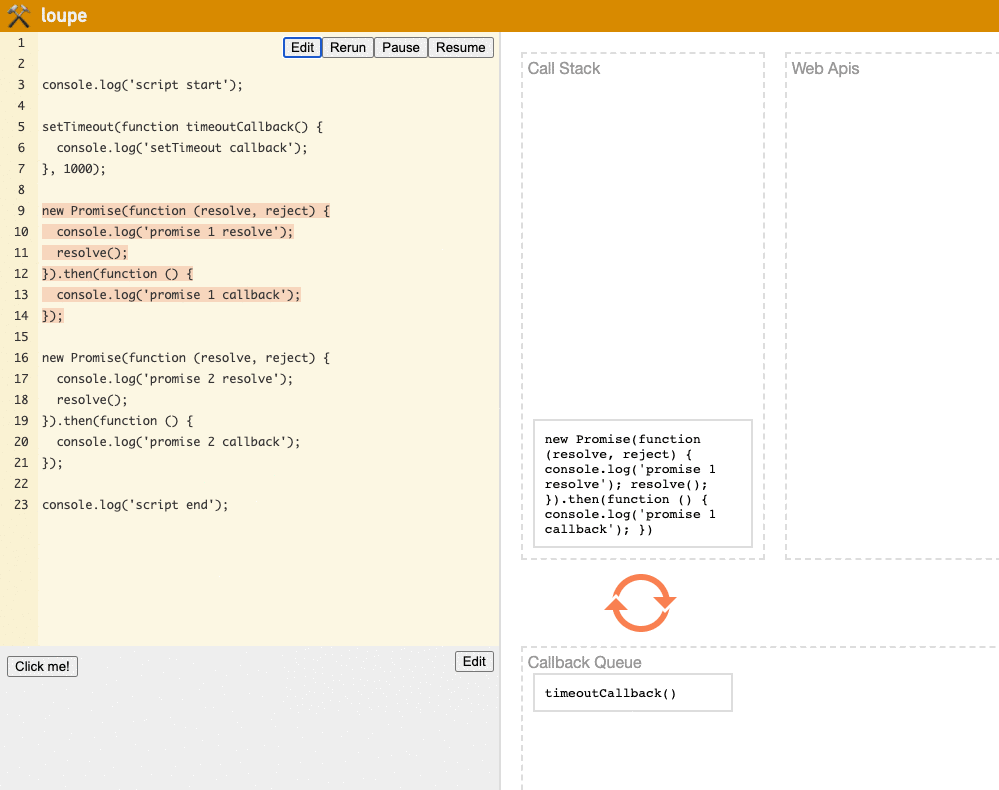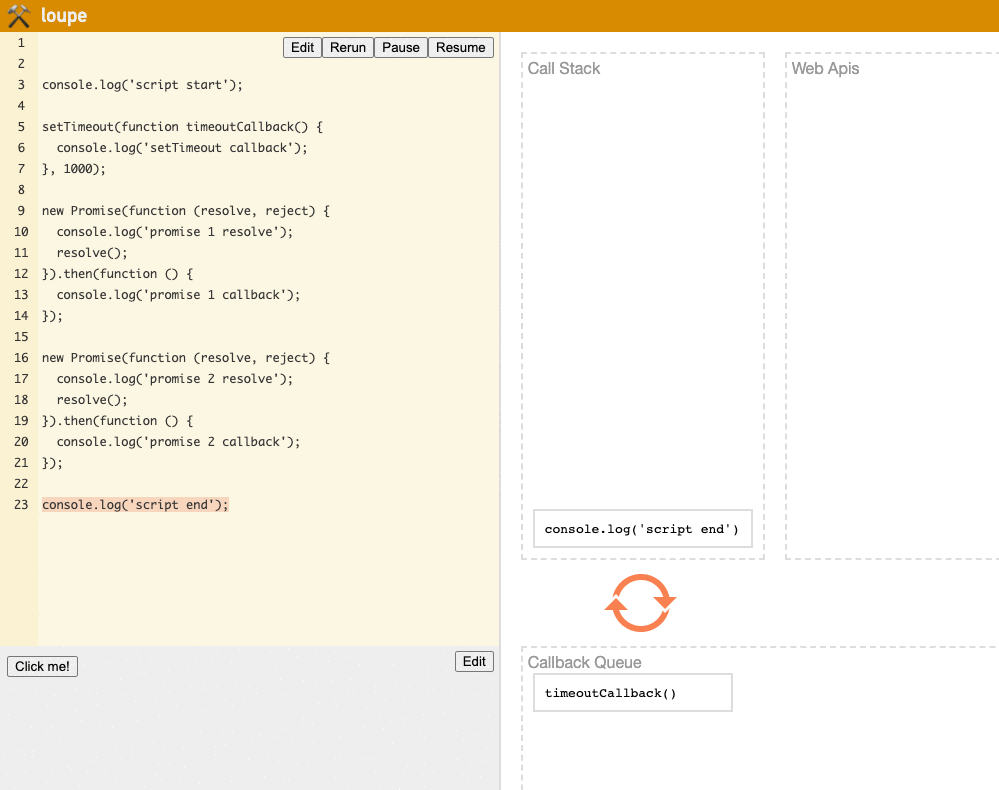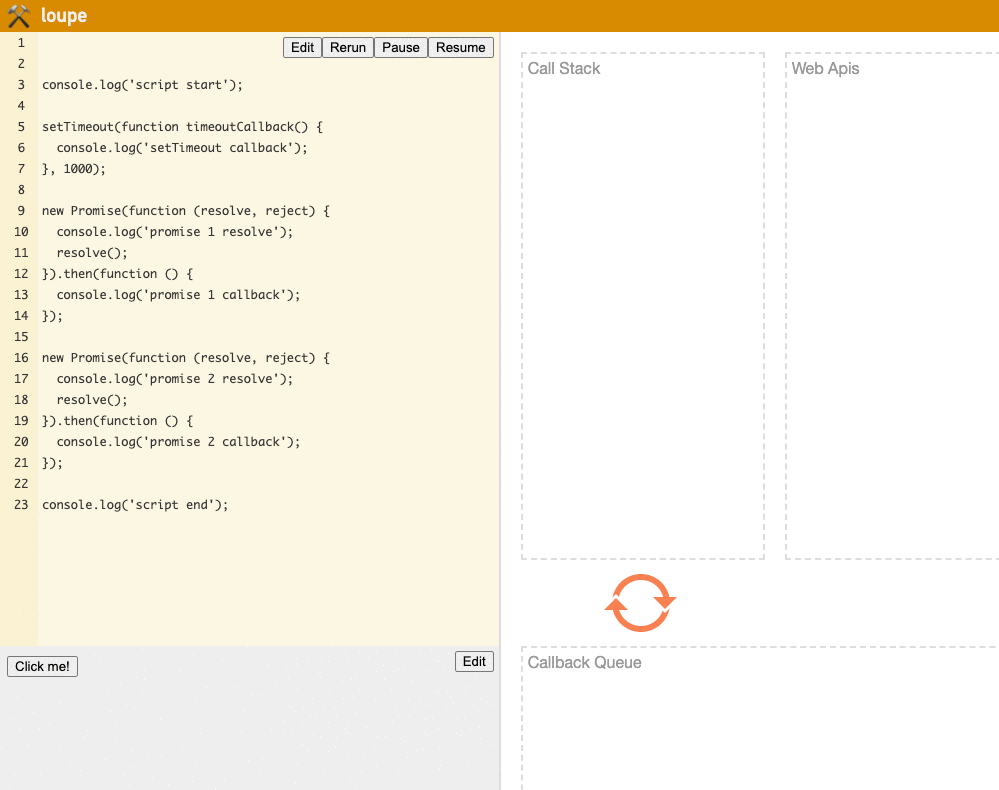 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
This example is quite important. If you can understand it, you'll have a good grasp of how the Event Loop works. If you're still not quite clear, you might want to go through it a few more times.
How to Avoid User Operation Lag Using setTimeout
There are at least two possibilities that can lead to user operation lag:
- An event task is triggered too frequently, causing that event to fill up the
Task Queueand squeeze out otherTasks. - An event task has a high processing cost, causing the
Call Stackto spend too much time executing just thisTask.
Of course, there are other possibilities, but let's focus on these two common scenarios.
Event Task Triggered Too Frequently
The most common examples are scroll and mousemove events. These two events are triggered extremely frequently during user operations. If not handled properly, they can cause other Tasks to be blocked and unable to execute, leading to the perception that the webpage is problematic.
Here's a scenario with onClick and onMousemove events:
// In the lower left area of Loupe, mouse movement over the entire document area will trigger the mousemove event
$.on('document', 'mousemove', function onMousemove() {
console.log('Mousemove Callback Execute');
});
// In the lower left area of Loupe, clicking the Click Me button will trigger the click event
$.on('button', 'click', function onClick() {
console.log('Click Callback Execute');
});
Let's look at the result:
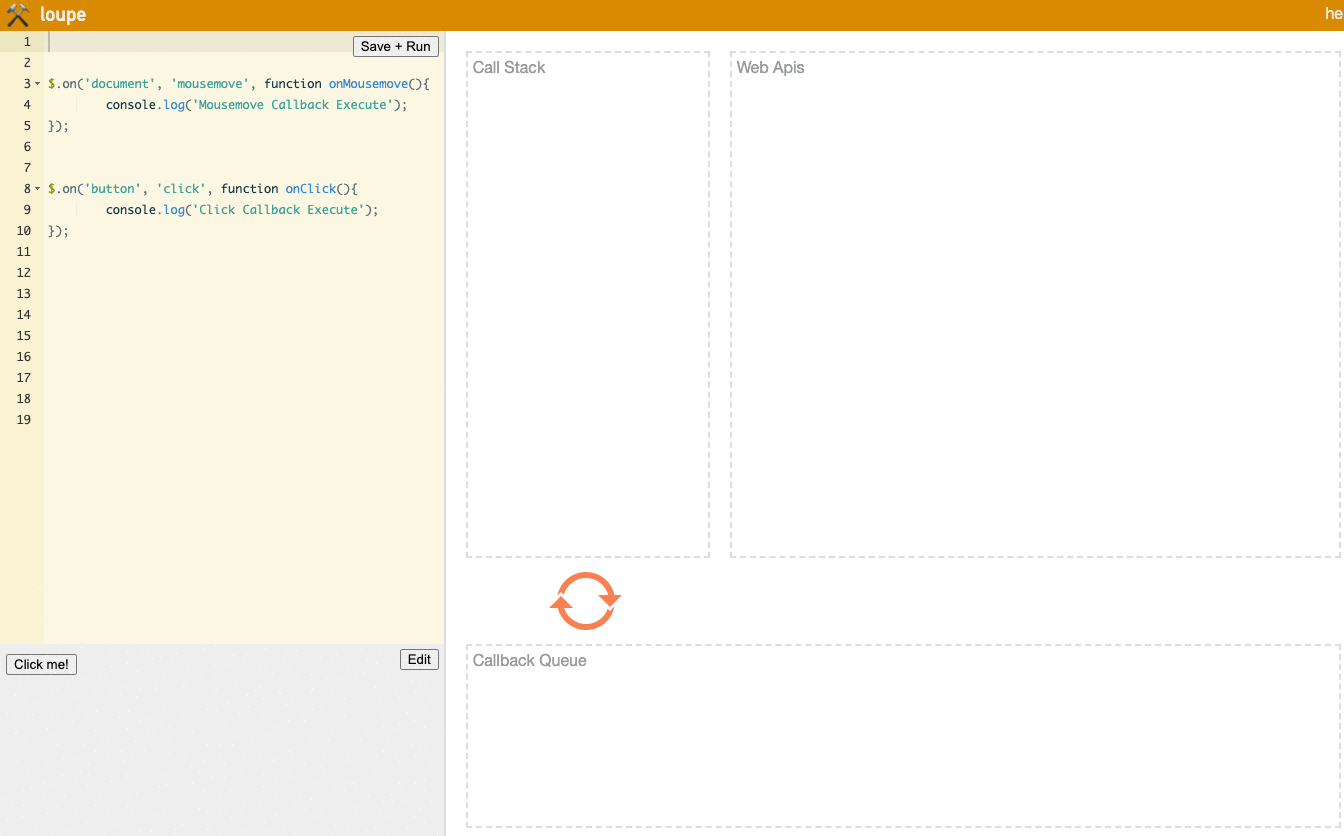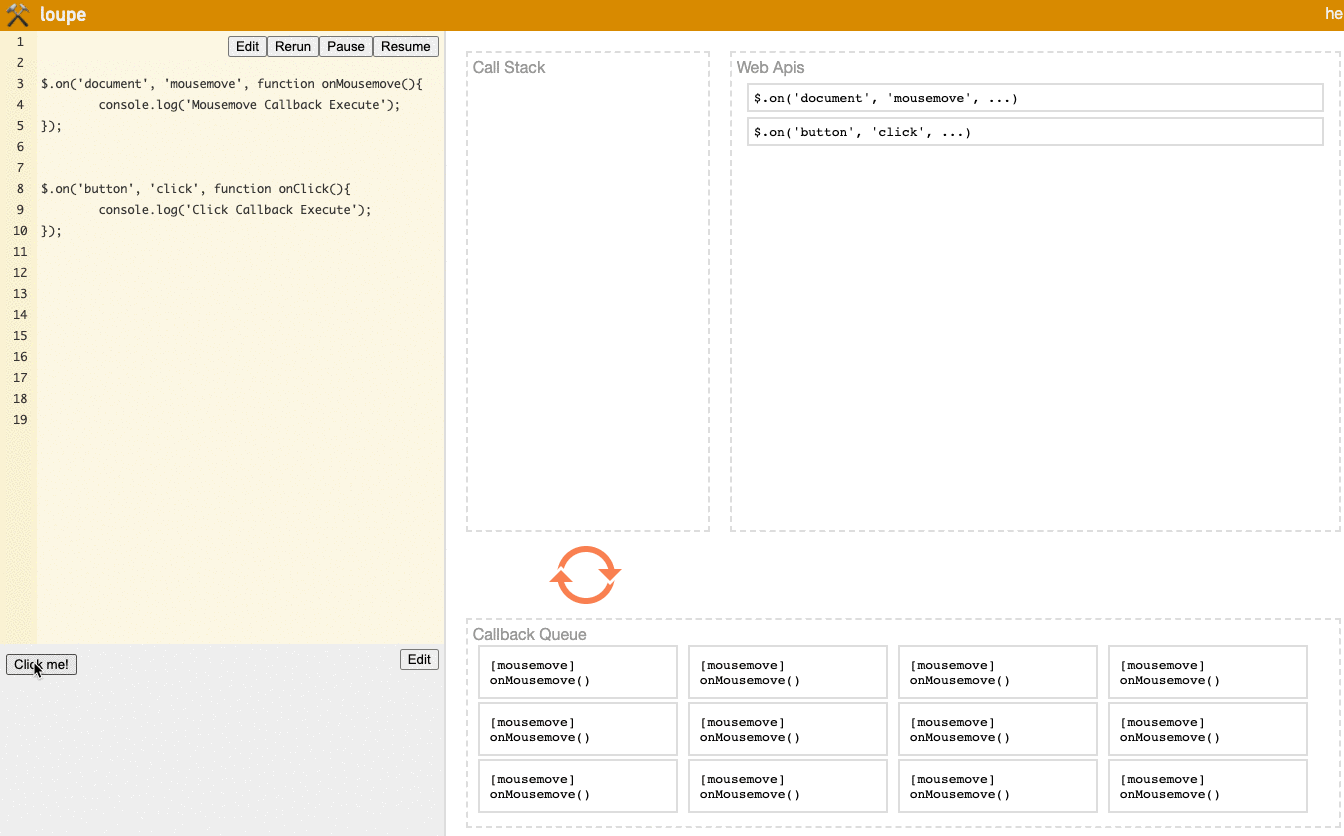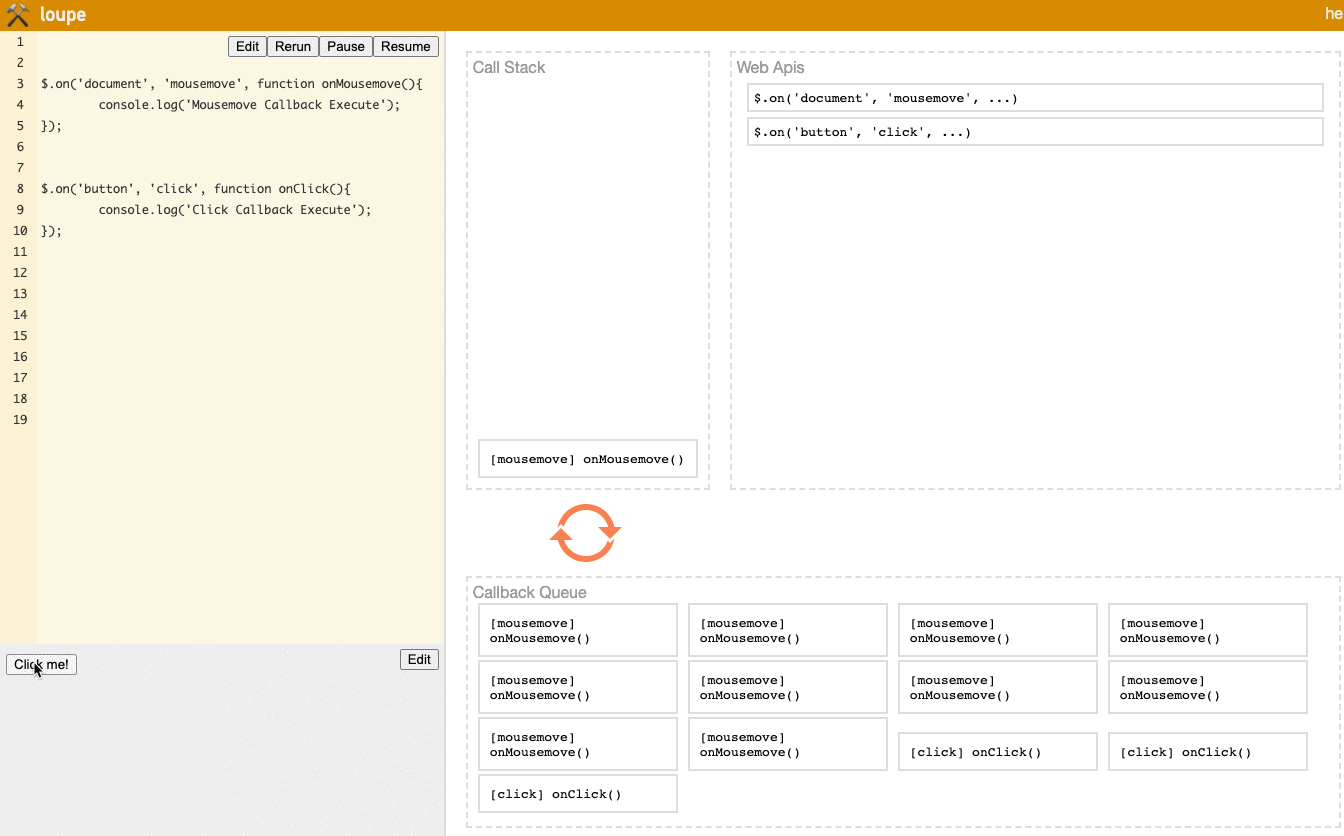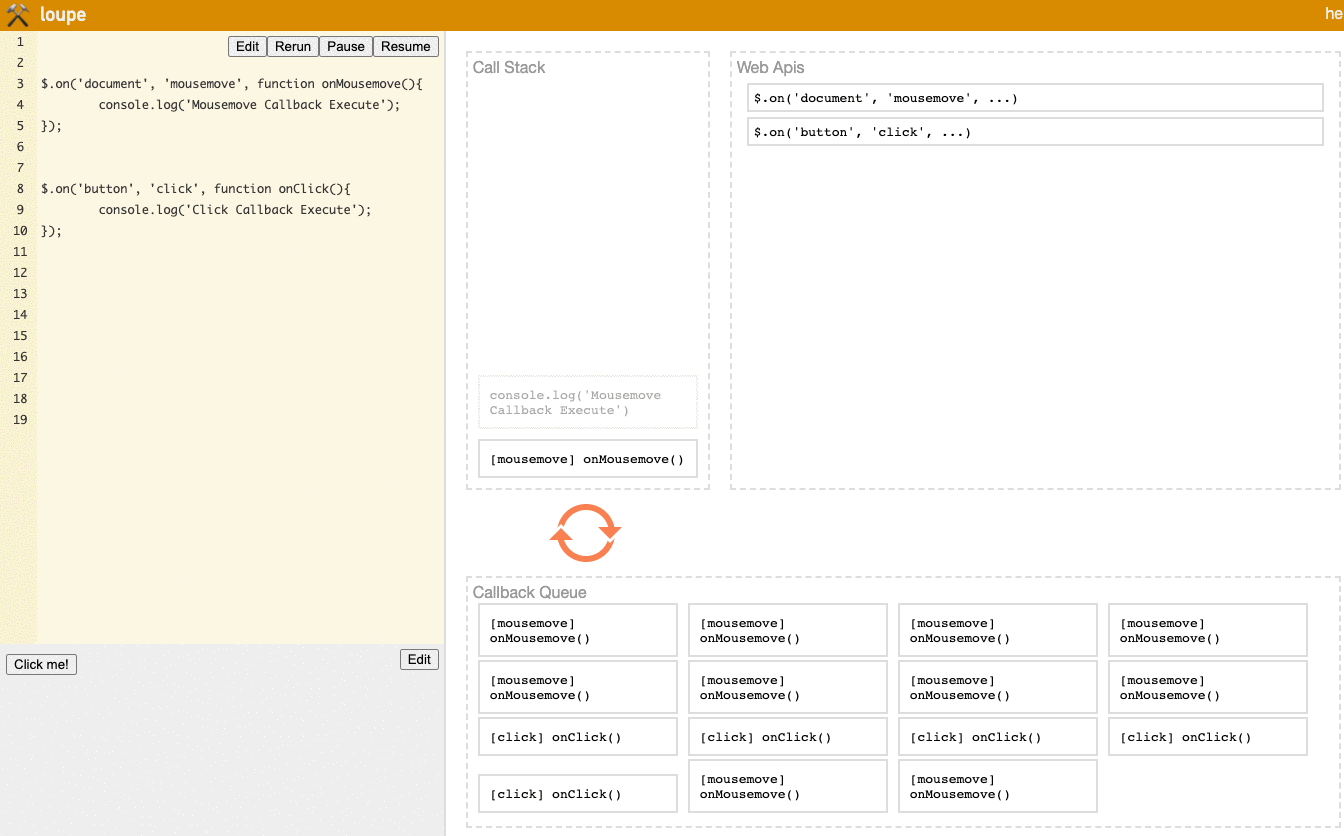 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
Notice the Task Queue area in the lower right. You'll see that when you first move to the Click Me button, many mousemove events are already triggered. So no matter how many times you click the button afterward, the onClick event will always be after a large group of onMousemove events, so Click Callback Execute will be blocked by Mousemove Callback Execute and unable to execute.
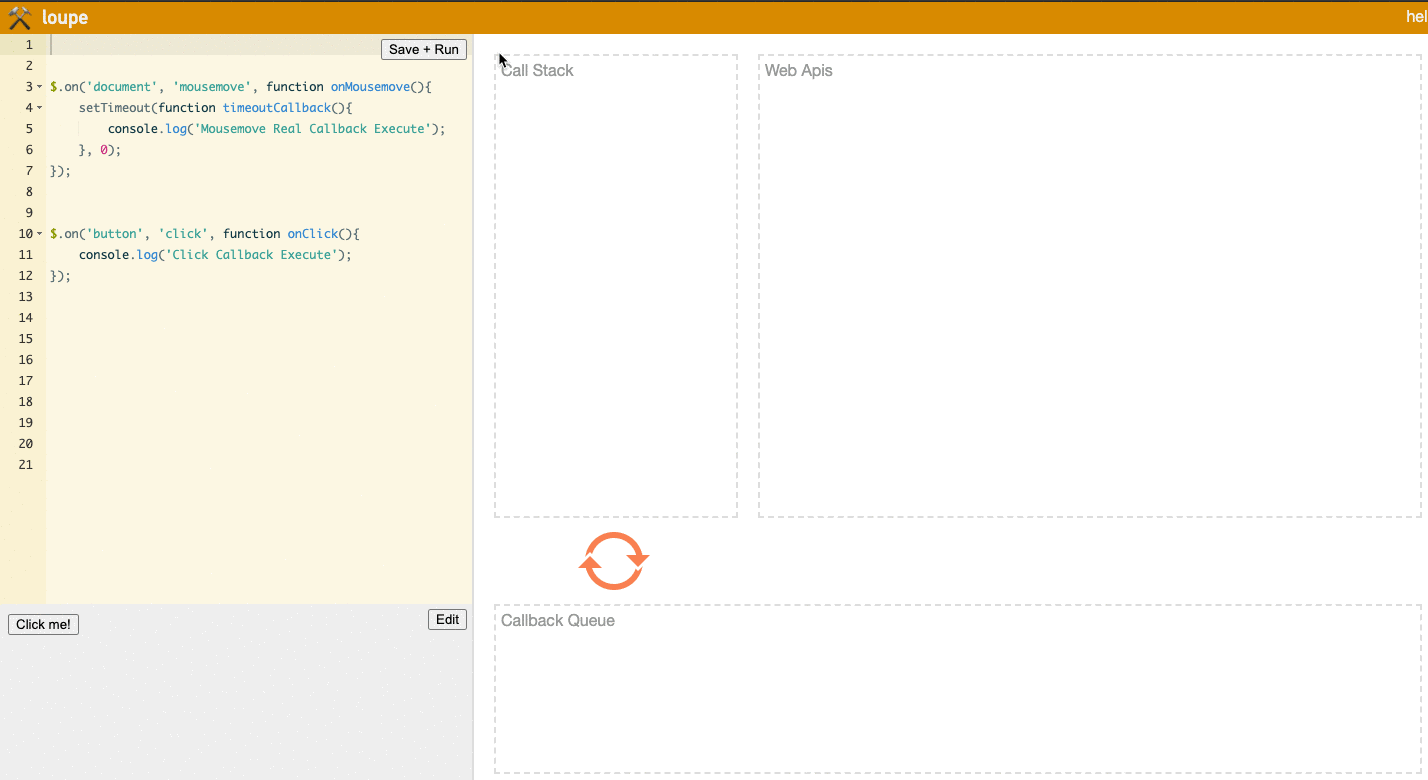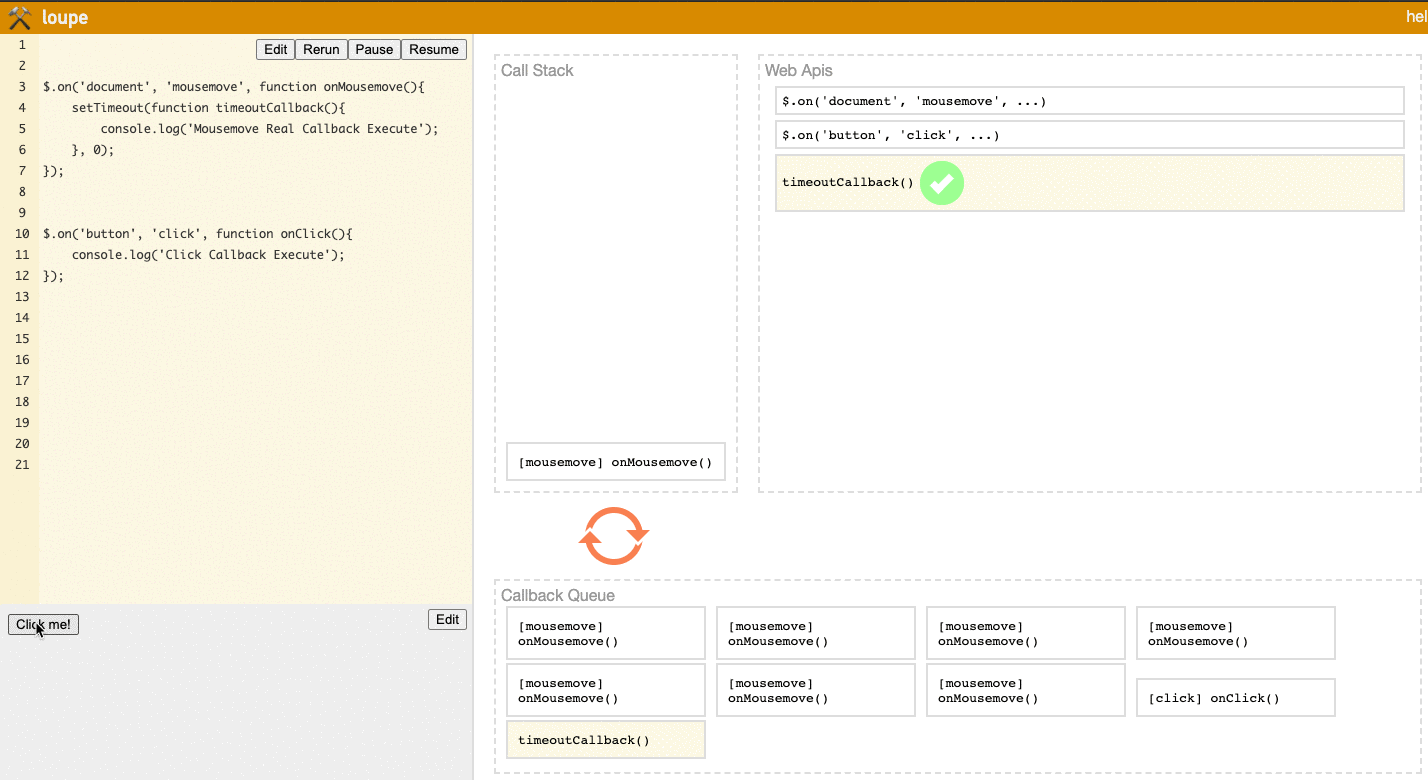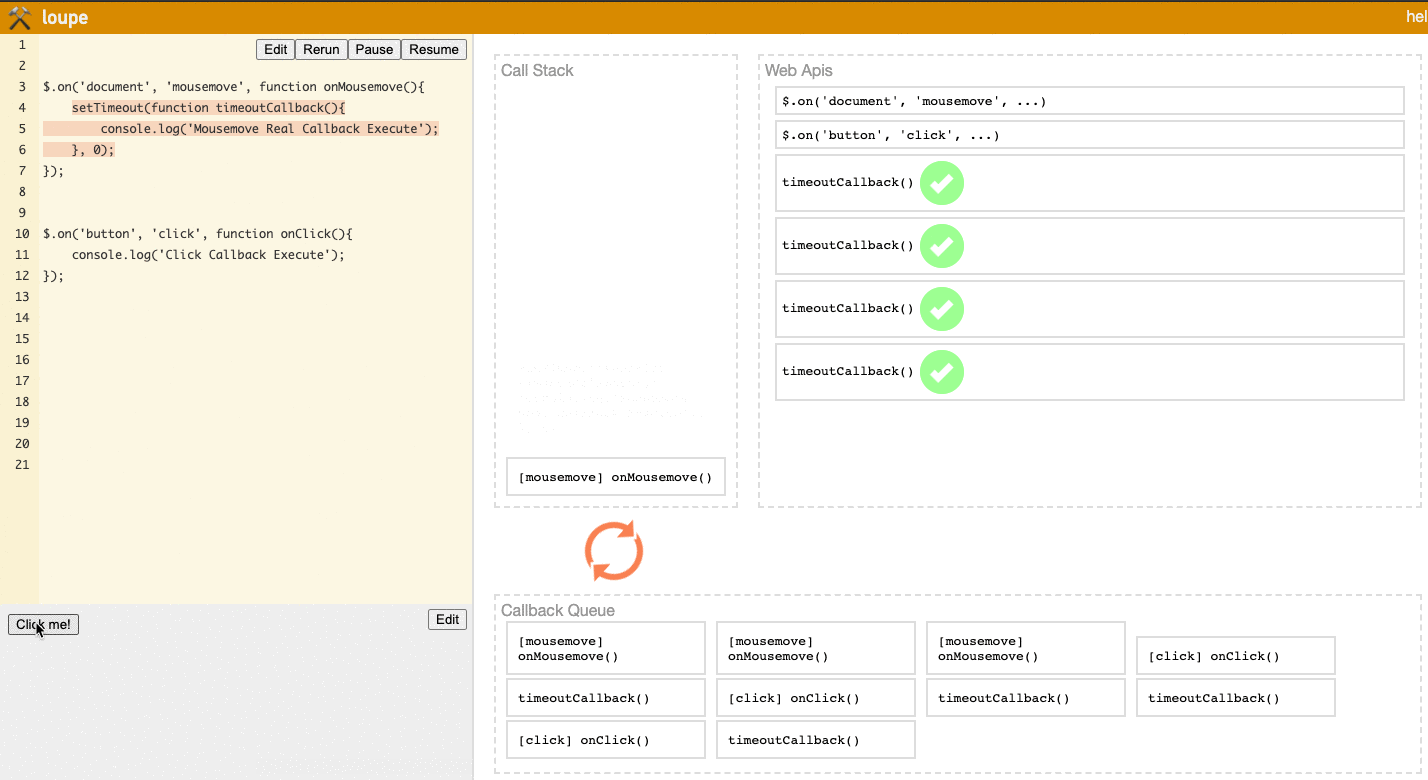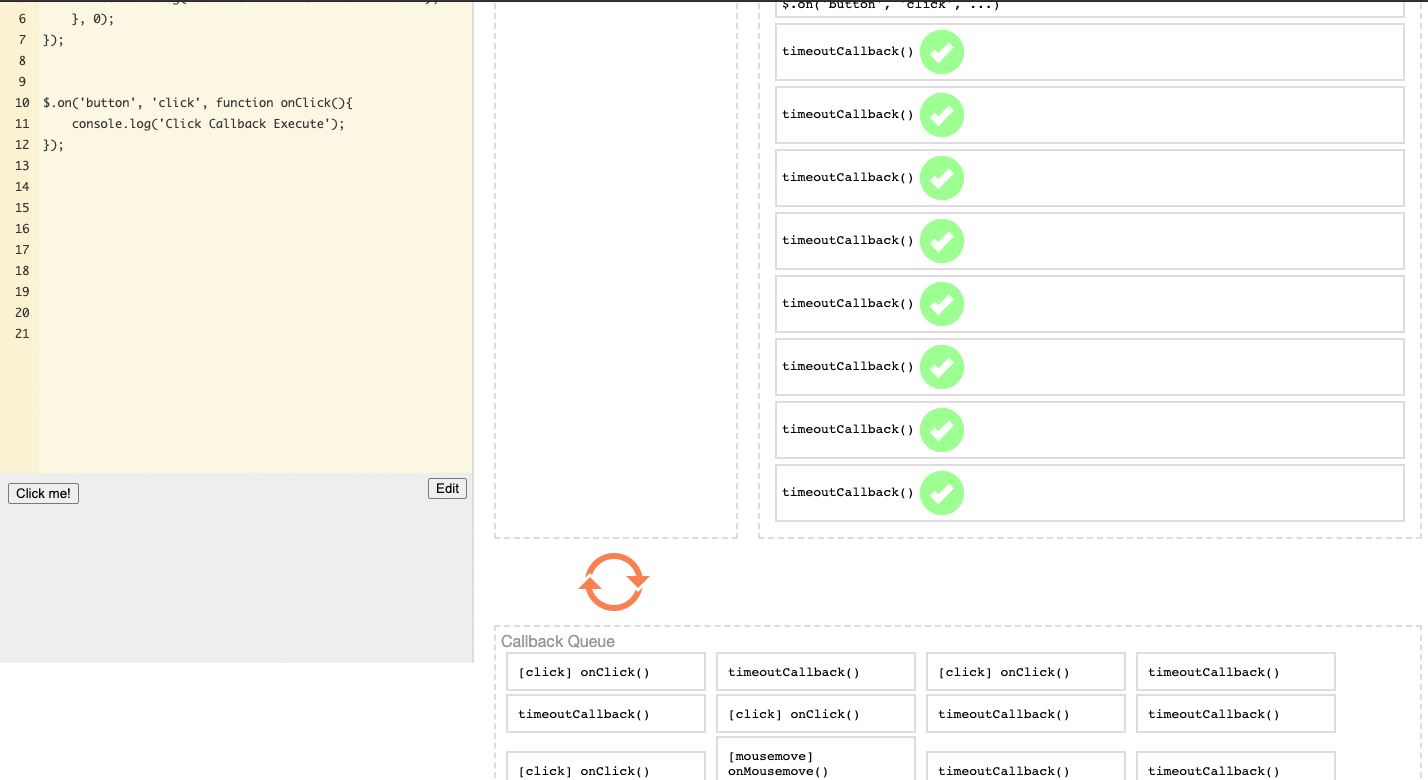
To solve this problem, we can use setTimeout.
Instead of directly triggering the Mousemove Callback Execute logic when mousemove is triggered, we first trigger setTimeout, so Mousemove Callback Execute is first queued in the Web API before being queued in the Task Queue.
// In the lower left area of Loupe, mouse movement over the entire document area will trigger the mousemove event
$.on('document', 'mousemove', function onMousemove() {
// Using setTimeout to allow Click Callback Execute to execute between Mousemove Callback Execute calls
setTimeout(function timeoutCallback() {
console.log('Mousemove Real Callback Execute');
}, 0);
});
// In the lower left area of Loupe, clicking the Click Me button will trigger the click event
$.on('button', 'click', function onClick() {
console.log('Click Callback Execute');
});
Let's look at the result:
 (Try it yourself on the loupe website)
(Try it yourself on the loupe website)
Notice the Task Queue area. You'll see that the onClick event now has a chance to insert itself between timeoutCallback events, meaning Click Callback Execute will execute between Mousemove Callback Execute events, rather than being blocked after all the Mousemove Callback Execute events.
So using the asynchronous concept of setTimeout has a chance to solve (or alleviate) the first problem.
Note: For handling frequently triggered events, the extended concepts are Debounce and Throttle.
Event Task with High Processing Cost
Generally, browsers try to update the page 60 times per second to keep the display running smoothly. In other words, they update the screen once every 16 ms.
We can see that in the last phase of the Event Loop, it's about drawing and updating the screen. So ideally, in one cycle, "the Task and all the generated Microtasks should be completed within 16 ms" to safely guarantee the smooth operation of the screen.
When a Task takes too long to process, it can lead to a situation where user operations lag. Therefore, if this occurs, we can break down the Task into smaller sizes to reduce the time cost of each executing Task.
I'll use an example from page 410 of Secrets of the JavaScript Ninja, Second Edition to illustrate.
Suppose we have the following code that performs a high time-cost task:
const tbody = document.querySelector('tbody');
// Create 20000 table rows in the tbody at once
const rowCount = 20000;
for (let i = 0; i < rowCount; i++) {
const tr = document.createElement('tr');
// For each table row, create 6 data columns, each column containing 1 text node
for (let t = 0; t < 6; i++) {
const td = document.createElement('td');
const tdText = document.createTextNode(`${i}-${t}`);
td.appendChild(tdText);
tr.appendChild(td);
}
tbody.appendChild(tr);
}
This code will create tens of thousands of DOM nodes and insert text, which is very costly to execute and can easily hinder user interaction with the page.
We can use setTimeout to break the Task into smaller pieces, allowing the page to render and interact more smoothly:
// Divide 20000 into 4 stages of execution
const rowCount = 20000;
const devideInto = 4;
const chunkRowCount = rowCount / devideInto;
let iteration = 0;
const tbody = document.querySelector('tbody');
const generateRows = () => {
// Create 5000 table rows in the tbody at once
for (let i = 0; i < chunkRowCount; i++) {
const tr = document.createElement('tr');
// For each table row, create 6 data columns, each column containing 1 text node
for (let t = 0; t < 6; t++) {
const td = document.createElement('td');
const tdText = document.createTextNode(`${i}-${t}`);
td.appendChild(tdText);
tr.appendChild(td);
}
tbody.appendChild(tr);
}
iteration++;
// If not yet complete, move generateRows to Web API again to throw into Task Queue
// Using setTimeout to transform the Task of executing 20000 rows once into a Task of executing 5000 rows 4 times
if (iteration < devideInto) setTimeout(generateRows, 0);
};
// Start generateRows, move generateRows to Web API then throw into Task Queue
setTimeout(generateRows, 0);
The conceptual difference in execution results is as follows (image from page 412 of the book):

The most important difference is that the task that originally took a long time to complete is broken down through setTimeout, allowing the web page to redraw and possibly insert new tasks (managed by the browser) in between, thus avoiding having the screen freeze for an extended period.
In the above example, setting setTimeout to delay by 0 seconds doesn't mean it will execute after exactly 0 seconds, but rather at least 0 seconds later. The meaning is close to notifying the browser to execute the callback Task as soon as possible. But at the same time, it gives the browser the right to readjust between divided Tasks (e.g., redrawing the screen).
Summary: Answering the Questions from the Introduction
At this point, we should be able to answer the questions mentioned in the introduction:
1. Why can JavaScript execute tasks asynchronously?
Because different execution environments have different APIs to assist with asynchronous task execution.
For example, in the Browser execution environment, asynchronous tasks such as setTimeout, setInterval timers or XHR network requests are all assisted by Web APIs. This allows single-threaded JavaScript running in the Browser to execute multiple tasks simultaneously.
2. What is the Event Loop?
The Event Loop is a mechanism in the JavaScript execution environment that handles the execution order of asynchronous tasks.
For example, in the Browser execution environment, asynchronous tasks are handled by Web APIs, which, after processing, typically have Callback Tasks. These Tasks are thrown into the Callback Queue to wait until the right time, at which point they're thrown into the Call Stack for execution.
The Event Loop is the mechanism that handles the execution order of asynchronous tasks from the Callback Queue to the Call Stack, including the operation flow of Tasks and Microtasks.
3. What are Tasks and Microtasks?
In JavaScript, tasks are divided into two types: Tasks (macrotasks) and Microtasks.
Tasks are independent work units, including: script execution, setTimeout/setInterval callbacks, DOM event callbacks, etc. These are queued in the Task Queue to await execution.
Microtasks are smaller compared to Tasks and generally less performance-intensive. They need to be executed as early as possible to help update data states before the screen is rendered. These are queued in the Microtask Queue to await execution.
In one cycle of the Event Loop, at most one Task is processed, with the rest continuing to wait in the Task Queue, but all Microtasks are processed, emptying the Microtask Queue.
4. How does the Event Loop work?
In one cycle of the Event Loop:
- We first check if there are any
Tasksin theTask Queue. - If there is a
Task, we execute it; if not, we proceed directly to checking theMicrotask Queue. - After completing a
Task, we check if there are anyMicrotasksin theMicrotask Queue. - If there are
Microtasks, we execute them, and we only proceed to the nextrenderphase after completing allMicrotasksin theMicrotask Queue. - If rendering is needed, we render; if not, we don't execute. Then we return to step 1.
5. How can we prevent lag caused by high-cost Event handling?
Usually, it could be due to "event triggering frequency being too high" or "event processing time cost being too high", both of which can be addressed through setTimeout or its derivatives like throttle or debounce.
-
Event triggering frequency being too high:
setTimeoutcan make the event'sTaskfirst enterWeb APIsfor a countdown, and then be thrown into theTask Queue. During the countdown period inWeb APIs, other eventTaskscan be inserted into theTask Queuefor execution, rather than always being blocked at the end. -
Event processing time cost being too high:
setTimeoutcan break a high-cost singleTaskinto multipleTasks, allowing the browser to redraw or insert other tasks in between.
Concluding Thoughts
To be honest, there's much more content and detail that could be explored about the Event Loop, such as directly reading the HTML specification document, but the concepts covered so far should be sufficient for many asynchronous development scenarios. Of course, they're also useful for interview scenarios!
The content below provides some practical code examples to test your understanding of what gets printed out in what order.
I suggest thinking about each example before scrolling down to see the answer.
Finally, Some Challenges with Mixed Promise and setTimeout Execution
// What is the order of the English outputs?
function fn1() {
console.log('a');
}
function fn2() {
console.log('b');
}
function fn3() {
console.log('c');
setTimeout(fn1, 0);
new Promise(function (resolve) {
resolve('d');
}).then(function (resolve) {
console.log(resolve);
});
fn2();
}
fn3();
- Initially, the running
mainline scriptitself is aTask, and theTaskbegins to run. fn3is triggered and begins to execute, then printsc.setTimeoutis triggered, andfn1is thrown into theTask Queuevia theWeb API.promiseis triggered, andconsole.log(resolve)is thrown into theMicrotask Queue.fn2is triggered and begins to execute, then printsb.- The main thread's
Taskends, and we begin to executeMicrotasks, executingconsole.log(resolve), which printsd. - We enter the next round of the Event Loop, find
fn1in theTask Queue, and execute it, printinga.
The result is: c -> b -> d -> a.
// What is the order of the English outputs?
function fn1() {
console.log('a');
}
function fn2() {
setTimeout(function () {
new Promise(function (resolve) {
console.log('b');
resolve('c');
}).then(function (resolveValue) {
console.log(resolveValue);
});
}, 0);
console.log('d');
}
function fn3() {
console.log('e');
setTimeout(fn1, 0);
new Promise(function (resolve) {
console.log('f');
resolve('g');
}).then(function (resolveValue) {
console.log(resolveValue);
});
fn2();
}
fn3();
This is an extension of the previous example. It's particularly important to note that the executor (callback) of a Promise is executed synchronously, while the callback of then is executed asynchronously.
The result is: e -> f -> d -> g -> a -> b -> c.
You can try it yourself on Loupe
setTimeout(function onTimeout() {
console.log('timeout callback');
}, 0);
Promise.resolve()
.then(function onFulfillOne() {
console.log('fulfill one');
})
.then(function onFulfillTwo() {
console.log('fulfill two');
});
function innerLog() {
console.log('inner');
}
innerLog();
console.log('outer');
This example uses some different syntax, but the concept is the same as above. It's worth noting that all Microtasks (then callbacks) will be executed before entering the next cycle.
The result is: inner -> outer -> fulfill one -> fulfill two -> timeout callback.
console.log('script start');
async function asyncOne() {
await asyncTwo();
console.log('async one');
}
async function asyncTwo() {
console.log('async two');
}
asyncOne();
setTimeout(function onTimeout() {
console.log('timeout callback');
}, 0);
new Promise(function (resolve) {
console.log('promise executor');
resolve();
}).then(function onFulfill() {
console.log('fulfill');
});
console.log('script end');
This example requires special attention to the syntactic sugar of Promise: async and await. It's quite simple: in an async function, if you "encounter await," it's executed synchronously (similar to in the executor); if you "don't encounter await," it's executed asynchronously and is thrown into the Microtask Queue to wait.
The result is: script start -> async two -> promise executor -> script end -> async one -> fulfill -> timeout callback.
Among these, script start -> async two -> promise executor -> script end is the Task phase of the first cycle, async one -> fulfill is the Microtask phase of the first cycle, and timeout callback is the Task phase of the second cycle.
If you still don't understand some of the content in the examples above, I would recommend reading this article again, or directly reading the reference documents below. There might be articles that are more suitable for your learning style!
References
- 所以說 event loop 到底是什麼玩意兒?| Philip Roberts | JSConf EU
- 我知道你懂 Event Loop,但你了解到多深?
- Day 11 [EventLoop 01] 一次弄懂 Event Loop(徹底解決此類面試問題)
- JS 原力覺醒 Day15 - Macrotask 與 MicroTask
- 忍者 JavaScript 開發技巧探秘第二版:Chapter13 搞懂事件
Special Thanks
- Thanks to hikrr for pointing out in this issue that "setTimeout(fn, 1000) should be 1s not 0.1s", which has been corrected.