淺談前端錯誤發生時的處理機制,從畫面層到監控層
前言
在軟體專案中,錯誤處理是很重要的一塊,涵蓋範圍很廣,且針對不同的產品性質也有不同的錯誤處理和監控方式。在本文分享的是「前端錯誤發生時的處理機制」,而且會偏向「泛用型」的整體概念和簡要實作,適用於不同種類的產品。
因為在過往專案中,有過碰到部分優化前端處理錯誤的項目,包含錯誤畫面、錯誤記錄、錯誤監控等等,藉此讓錯誤發生時能更快地查找問題、修復問題。剛好近期想梳理前端錯誤處理的概覽,因此順道分享,讓有需要的人可以參考囉。
基本上期望達到的目標是有了「前端錯誤發生時的處理機制」後:
- 當使用者主動提供錯誤截圖後,開發團隊能更有效率地進行修復 => 對應錯誤畫面
- 當使用者只提供錯誤時間後,開發團隊能自行獲得更多資訊開始修復 => 對應錯誤記錄
- 當使用者發生錯誤時,即便沒有主動通知,開發團隊能自行開始修復 => 對應錯誤監控
本文主要分成以下段落:
- 前端錯誤處理系統概覽
- 錯誤畫面處理
- 錯誤紀錄處理
- 錯誤監控處理
- 重點整理與回顧
在錯誤畫面、紀錄、監控的章節中,會包含詳細的「概念說明」以及簡單的「實作概要」。
關於實作概要的部分,其中程式碼只會是概念的示意,細節大多會省略,重點在於知道為什麼做、怎麼做而已,但不會是手把手帶著做。至於技術工具,則會用到 Next.js、GCP Logging / Monitoring 以及 Slack 示範,但範例都是簡單通用的概念,即便不熟悉上述技術工具也能大方向理解,當然也可以用其他技術工具實踐相同概念。
另外,網頁中的錯誤類型很多,本文不多做介紹,會直接以「React error boundary」抓到的 Unexpected error 作為示範,但實作概念是可以套用到不同錯誤類型。
是說標題中有“淺談”,是因為我認為內容偏淺,比較適合「尚未實作過錯誤處理和監控的前端工程師」,如果你已經知道如何抓 Error 顯示畫面、送 Error 到 Log、跳錯誤 Error 到 Slack,那就大概不需要閱讀了哦。
我認為理解完這篇後,比較是對擴展前端的廣度,更理解全局觀,但技術不深。
總之,期望閱讀完後能夠:
理解基本的前端錯誤處理與監控機制全貌,並大致理解能如何實作之。
前端錯誤處理系統概覽
通常想到前端錯誤處理,會直覺認為就是發生錯誤時的「錯誤畫面」顯示而已,但如果只這樣考量就比較侷限在單點思考,而非全局觀,除了畫面之外,至少還有「錯誤紀錄」、「錯誤監控」的設置,才能讓錯誤處理的流程系統更加完善,能讓除錯效率變高。
通常技術實作的背後,都有個為什麼,因此先談談為什麼需要有「錯誤畫面」、「錯誤紀錄」、「錯誤監控」?
為什麼需要錯誤畫面
如果發生錯誤時,連錯誤畫面都沒有,那麼就會造成兩個狀況:
- 使用者遇到功能問題,根本不知道發生什麼事,也不知道該怎麼辦
- 使用者想要反映問題,但也無法提供任何有意義的截圖畫面
所以呢,當使用者遇到錯誤時顯示設計好的錯誤畫面,除了能讓使用者體驗比較好外,畫面上也需要有部分資訊,讓開發者看到錯誤截圖後,可以更快地辨別、查找、解決問題。
好的錯誤畫面,讓使用者看到後,知道如何行動; 讓開發者看到後,獲得除錯初步資訊。
為什麼需要錯誤紀錄
如果使用者連截圖都沒給,只提供一個錯誤發生時間,那該怎麼辦?
如果錯誤是跟使用者裝置或瀏覽器版本有關,光從畫面截圖是看不出來,也不好進一步詢問使用者,那該怎麼辦?
這時候,若在錯誤發生時,有把查詢錯誤所需要的詳細資訊紀錄到某個地方,就能解決這個問題。即便使用者只給錯誤發生時間,開發者也能只用時間去查詢錯誤的詳細資訊,藉此推測錯誤原因或者還原錯誤情境,進而修復之。
通常稱呼這個紀錄的資訊叫做「Log(日誌)」。大部分公司都會將 Log 送到第三方服務儲存,像是:Sentry 或 Cloud Logging 之類,除了不用維護儲存點之外,那些服務通常也附帶不錯的查詢功能,這樣才能在大量 Log 中,快速找到想要查看的錯誤 Log。
好的錯誤紀錄,能讓開發者快速查詢到解決問題所需要的錯誤細節。
p.s.1 用第三方服務雖然不需要維護之,但通常要付錢啦,所以也需要考量成本問題,尤其 Log 量大時。
p.s.2 送 Log 時,要避免把紀錄敏感資料紀錄,不然會有資安問題,在下面錯誤記錄的章節中會談更多。
為什麼需要錯誤監控
如果使用者尚未主動通知前,開發者就已經發現問題,並著手處理甚至修復之,那是不是會更有效率?
如果客戶尚未反映錯誤前,產品經理就已經知道問題,並準備好一套可以提供給客戶的完整說明,那是不是會讓客戶覺得都在可控範圍內?
這些都可以透過設置錯誤發生時的監控警告來達成。當有錯誤發生送進第三方服務時,可以設置特定錯誤條件的警告,發送通知到 Slack、Email 等等地方通知團隊,藉此讓團隊儘早查看錯誤 Log 並處理之,無需等到使用者反映問題才能處理。
這類錯誤監控機制,通常可以在第三方服務中設定,例如:Sentry、Cloud Monitoring。
順帶一提,錯誤記錄和監控不只能設定在 Production site,也能設置在 Staging / Dev site 。這樣的好處是,假設 release 功能到 Staging / Dev site 時,如果有錯誤警告跳出,就可以趕緊修復,讓在 Production site 的真實使用者不會遇到該錯誤。
好的錯誤監控,能化被動為主動,讓團隊提早處理錯誤。
為什麼「前端」需要關注錯誤處理
我認為軟體產品是由團隊負責,所以無論是團隊中的任何職能,都需要關心這個產品的錯誤狀況,只是每個職能關注的點不同,而身為前端工程師,需要特別需要關注的是:
- 有些錯誤發生在前端程式碼中,例如:前端元件報錯 Unexpected error (有可能是 API runtime 資料格式有誤、某些 API 不支援特定瀏覽器版本等等)。
- 有些客戶端資訊可由前端紀錄,例如:使用者發生錯誤所在的頁面網址、詳細裝置資訊、前端 APP 版號等,部分錯誤如果有這些資訊可以更快解決。
- 錯誤畫面需要有什麼資訊,能讓使用者體驗更好、讓開發者解決錯誤更有效率,這是涵蓋在前端錯誤處理的系統中。
從產品的角度來看,可以思考幾個問題來確認錯誤處理是否有做好:
- 如何讓使用者遇到錯誤後,知道發生什麼事、能做什麼?
- 如何讓使用者遇到錯誤後,僅提供錯誤時間或截圖,團隊就有機會處理好問題?
- 如何在發生錯誤時收到警告通知,藉此在使用者未主動反應前,團隊就能著手處理?
這些問題,如果有前端角色參與處理錯誤處理機制,就能更有效率地解決。
前端錯誤處理機制的全貌
綜合上述所提及的「錯誤畫面、記錄、監控」,大致可用下圖,示意前端錯誤處理機制的概念:
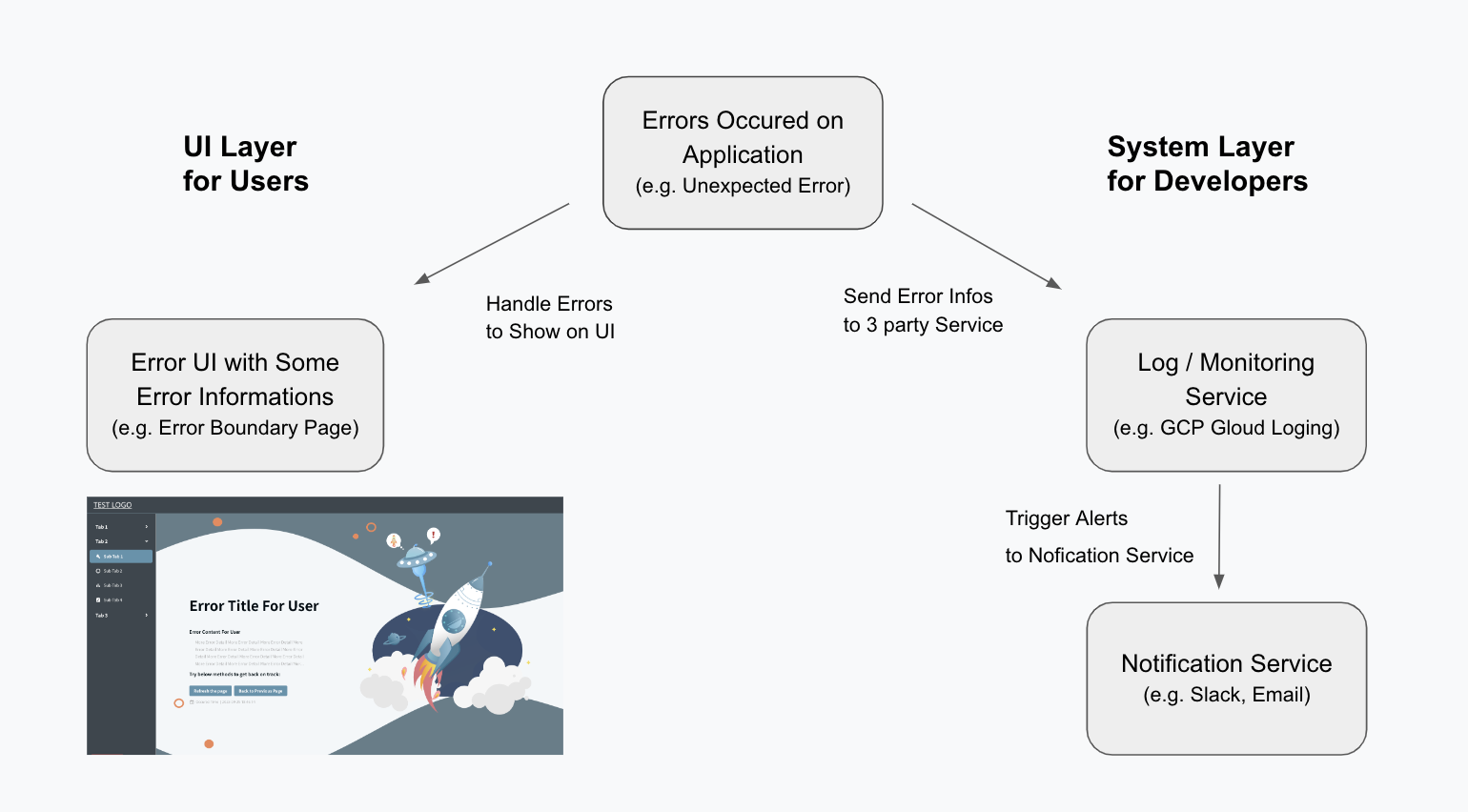
左邊的 UI Layer 屬於顯示給使用者的錯誤畫面; 右邊的 System Layer 包含錯誤記錄以及監控,是提供給開發者的工具。
當一個錯誤發生時,在使用者端,會看到錯誤畫面; 在開發者端,會接收到錯誤警告,而且可以進一步查詢錯誤記錄,獲取更多除錯所需的資訊。
這三個項目是彼此相關,但並非一定要全部一次到位。
真實情況下,團隊都有時間、人力資源等等的考量,很多時候並非一開始就完善,而且也沒必要,像是剛起步的新創產品何時 sunset 都不知道,無需立刻放資源完善全部。但通常在穩定獲利的完善產品中,會盡量完善這三者。
接著會深入談談這畫面、紀錄、監控層級各自需要注意的項目,以及簡要地實踐之。
畫面層級的處理
概念介紹
畫面的處理是前端本職所在,錯誤畫面需要顧及兩項重點:
- 使用者體驗:讓使用者知道發生什麼、還可以做什麼
- 開發者體驗:讓開發者知道初步的除錯資訊
關於使用者體驗,可以透過設計錯誤「標題」與「內容」讓使用者知道發生什麼事、設計操作「按鈕」讓使用者更直覺地知道可以怎麼做。
若使用者提供錯誤畫面截圖,畫面上有什麼訊息是能夠幫助開發者查詢呢?其實只要「錯誤標題或訊息」是設計過的,像是背後對應特定的 Error Code,那就能加速查詢。
但如果有實作「錯誤紀錄」,只要有「錯誤發生時間」就能查詢到錯誤發生的細節,藉此更快地推測問題原因和除錯。
以下為錯誤畫面示意圖,主要是注意資訊內容,UI 細節、好不好看可先忽略:
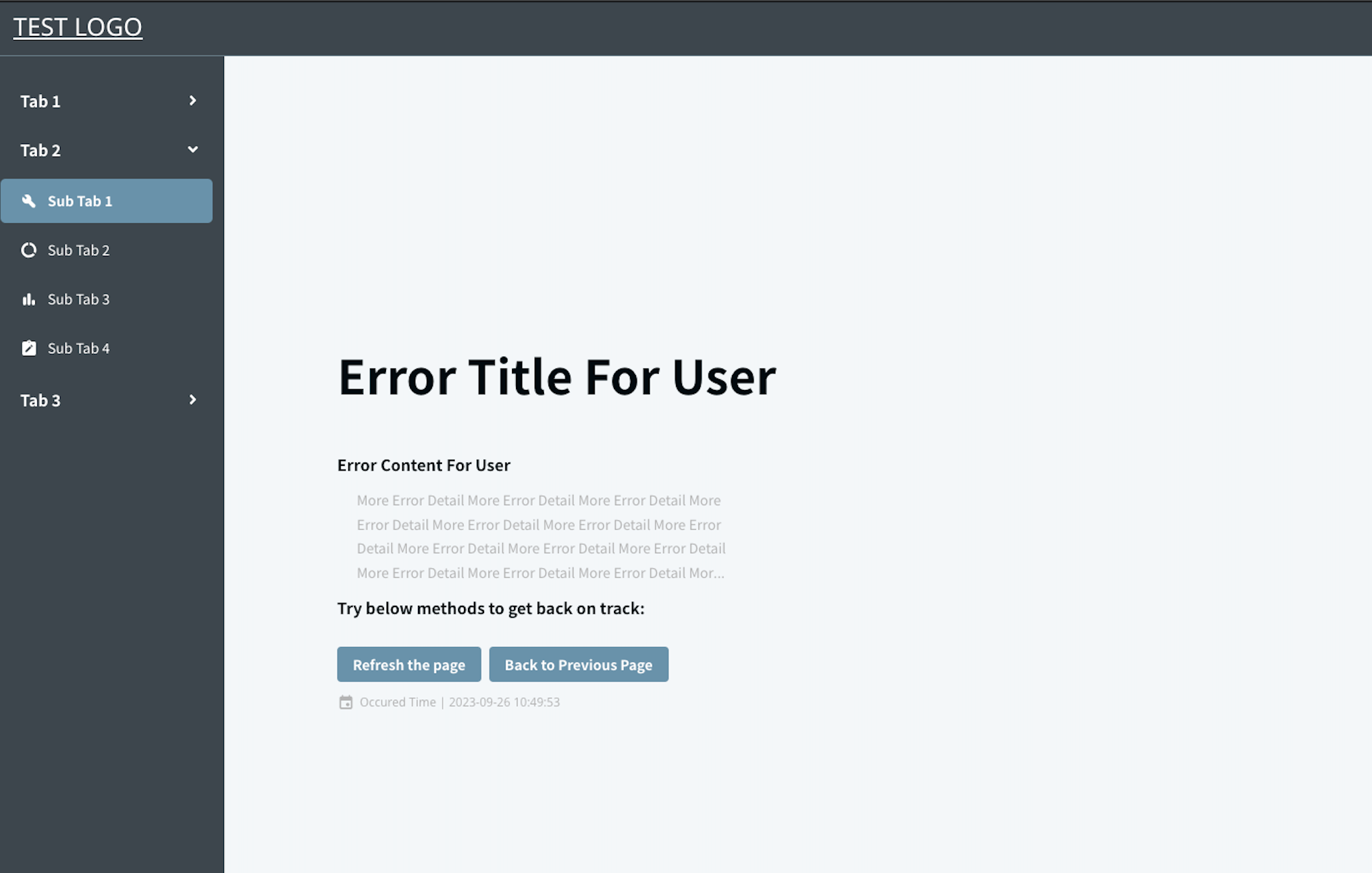 (Error Boundary Page 範例,有標題、內容、操作按鈕、錯誤時間)
(Error Boundary Page 範例,有標題、內容、操作按鈕、錯誤時間)
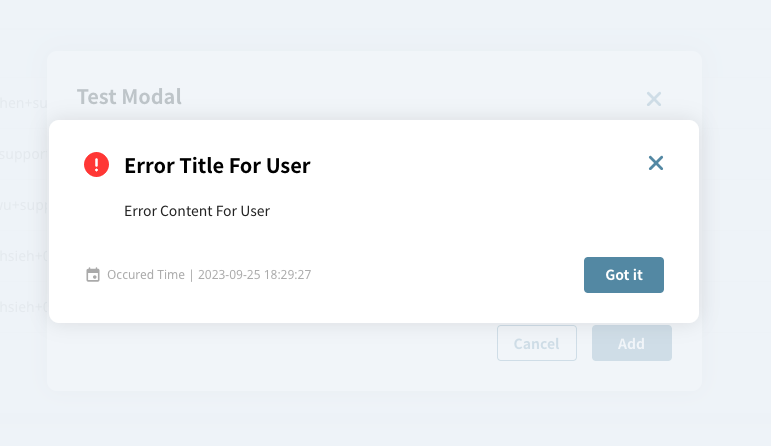 (Error Modal 範例,有標題、內容、操作按鈕、錯誤時間)
(Error Modal 範例,有標題、內容、操作按鈕、錯誤時間)
實作概要
錯誤畫面的實作上,要做的事情主要有兩件:
- 抓取錯誤:不同的錯誤類型會有不同的抓取方式,常見的有
try catch,window.onerror,addEventListener('error', function),error boundary等等。 - 畫出畫面:透過前端語言或框架,畫出顯示錯誤標題、內容、時間的錯誤畫面,並提供使用者操作用的按鈕。
本文中示範的是在 Next.js APP 中,透過 React error boundary 去抓取元件中 Unexpected errors,並顯示在客製化的錯誤畫面上。
p.s. 所有程式碼的實作可能因為工具版本不同而有所差異。
第一步是製作 ErrorBoundary class component:
/* ErrorBoundary.js file */
import ErrorFallback from './ErrorFallback'
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
// Init state
this.state = {
hasError: false,
error: null
};
}
static getDerivedStateFromError(error) {
// Update state so the next render will show the fallback UI.
return { hasError: true, error };
}
componentDidCatch (error) {
// You can catch unexpected error here and send log to your service.
// This log system will be built in the next chapter.
}
render () {
if (this.state.hasError) {
// You can render any customized fallback UI.
return (
<ErrorFallback
// for showing error info.
error={this.state.error}
// for refreshing the page.
resetError={() => {
this.setState({
hasError: false,
error: null
});
}}
/>
)
}
// If don't have error, then show original children component.
return this.props.children
}
}
export default ErrorBoundary
其中的 ErrorFallback UI 畫面就看產品經理、設計師與前端工程師決定該如何實作,舉例而言可以做成:
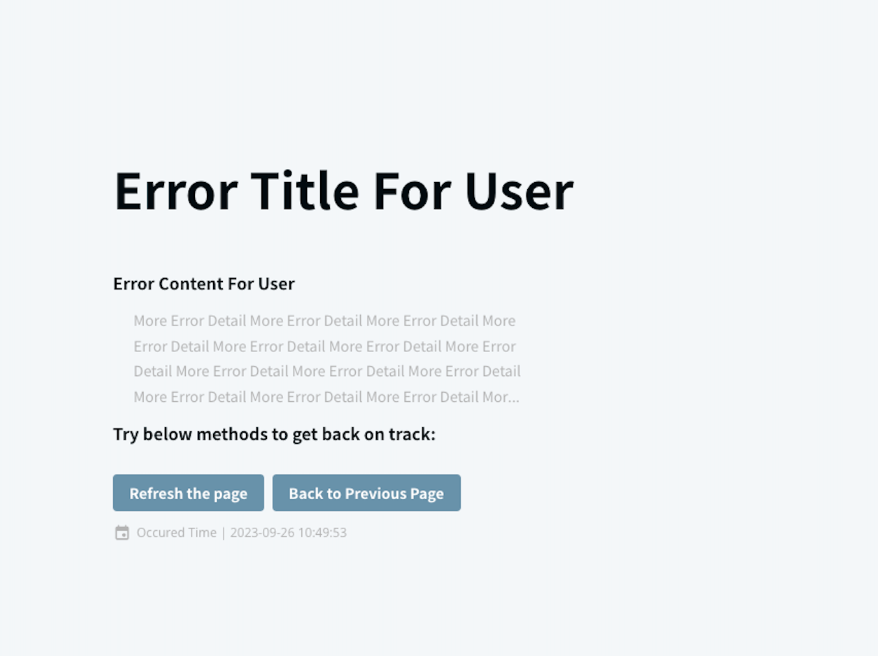 (Error Boundary Content 範例,有標題、內容、操作按鈕、錯誤時間)
(Error Boundary Content 範例,有標題、內容、操作按鈕、錯誤時間)
重點在於「使用者知道怎麼了、接著該怎麼做」、「開發者能獲得錯誤資訊,進一步查詢錯誤」即可,至於畫面體驗細節、內容如何呈現,則端看產品性質而定。
從程式碼中可看到 ErrorBoundary 在沒錯誤的情境,是回傳 this.props.children,代表 ErrorBoundary 是會包住 children 元件,所以接著就是第二步。
第二步是將 ErrorBoundary 包住要保護的 children component。
以本文範例而言,直接在 _app.js 檔案中處理,藉此讓「所有頁面」都被保護,如果在任何頁面遇到 Unexpected error 壞掉,都會顯示設計過的 Error Boundary 頁面。
/* _app.js file */
import Layout from '@component/Layout'
import ErrorBoundary from '@component/ErrorBoundary'
// ...(省略)
const MyApp = ({ Component, pageProps, ...... }) => {
// ...(省略)
return (
<Header>
......
</Header>
<Layout>
{/* Use ErrorBoundary to wrap all app Component. */}
<ErrorBoundary>
<Component {...pageProps} />
</ErrorBoundary>
</Layout>
)
}
// ...(省略)
因為實作的 Layout 中包含 Header 以及 Sidebar:
/* Layout.js file */
import Header from '@component/Header'
import Sidebar from '@component/Sidebar'
// ...(省略)
const Layout = ({ children }) => {
return (
<>
......
<Header />
<Sidebar />
{children} // This chidren will wrap by our ErrorBoundary
......
</>
)
}
// ...(省略)
所以最終發生 Unexpexted error 時,不會只有 ErrorBoundary 畫面,而是 Header + Sidebar + ErrorBoundary,如此一來,使用者還可以點擊 Header 或 Sidebar 上的按鈕,藉此去其他沒有壞掉的頁面做操作,體驗會更好。
(Error Boundary Page 範例,除了 ErrorBounday 畫面外,還有 Header、Sidebar 可操作)
但同時也要注意,假設今天 Unexpexted error 發生在 Header 或 Sidebar 時,是不會被目前設計的 ErrorBoundary 保護到,需要記得另外處理之,例如替它們包上其他 Boundary,在此不再贅述。
記錄層級的處理
概念介紹
紀錄層級是在錯誤發生時,把錯誤發生當下的資料記錄下來,方便後續查詢。
通常要紀錄什麼可以依據產品性質而定,例如:如果產品只是網頁,大多都用在 Mac 筆電而已,或許裝置作業系統不重要,但如果是 PWA 產品,會被安裝在各式各樣的裝置和作業系統上,那麼紀錄裝置與作業系統就會很重要。
以下是“可能”紀錄的資料:
- 紀錄前端 APP 版號:
- 說明:通常產品每次 release 後都會更新版號,有時紀錄版號能快速釐清問題。
- 例如:當在相同頁面與功能,只有部分使用者遇到問題,可以從錯誤訊息中,先確認是吃到哪個前端版本,說不定是部分使用者吃到前一個版本才有問題。
- 紀錄瀏覽器、裝置、作業系統等等資訊:
- 說明:如果產品會運行在多種瀏覽器、裝置、作業系統,那麼紀錄這個就很重要,
- 例如:發現錯誤 Log 很多,但團隊沒有遇到,後來經過裝置、作業系統細查,才發現在特定作業系統版號上才出錯,有 API 尚未支援。
- 紀錄當前頁面網址:
- 說明:通常產品會有多個頁面,有時紀錄頁面 path 與 query 能很快地找到問題。
- 例如:當發生 Unexpected error page crash 時,能快速知道是哪個頁面出事; 發現有支 API 在 A 頁面出事,但 B 頁面沒事,原來是 A 頁面中有資料格式有問題。
- 紀錄登入後相關資訊:
- 說明:通常產品都有登入功能,有時紀錄使用者資料或公司資料,能快速地找到問題。需要注意資安問題,不能紀錄到敏感資料。
- 例如:某些使用者少了某個編輯按鈕,發現原來是特定 role 的使用者畫面顯示有霧; 在相同頁面,未登入才發生問題,這也能從使用者資料看出,因為沒登入使用者 id 為空。
以上僅是一些舉例。
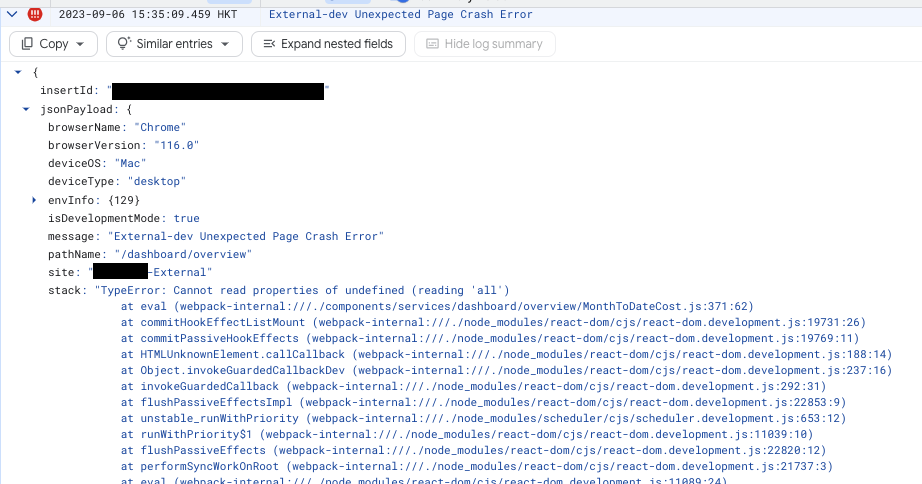 (單比 Log 資料的示意)
(單比 Log 資料的示意)
Log 會紀錄什麼資料會是「變動」的過程,可能一開始紀錄很多,後來發現用不掉,所以未來就不繼續紀錄; 可能一開始沒有紀錄到,後來除錯時才發現需要,所以未來補記。是可以持續優化的過程。
然而比起要紀錄什麼,「不可以紀錄」什麼更為重要:
不可以紀錄安全性敏感的資料,例如:不能紀錄使用者輸入的密碼,即便是輸入錯誤的密碼也不行,因為有錯誤密碼,就能更簡單推論出正確的密碼; 不能紀錄 token,不小心外洩就嚴重了; ......。總之,覺得是敏感資料都不要紀錄。
不要覺得怎麼會有人犯這種把密碼進入進去 Log 的錯誤,網站前端打 API 時把密碼加密,有意義嗎? 這篇 Huli 所寫的文章中,就有提到另一篇The case for client-side hashing: logging passwords by mistake 文章,其中有提及「Some big players such as Facebook, Twitter and GitHub have published incidents where plaintext passwords are logged.」附上各大公司把密碼送到 Log 系統的紀錄。
實作概要
錯誤紀錄的實作上,要做的事情主要有兩件:
- 封裝送 Log 的方法:不同的第三方服務實作的方式可能不同,都可以直接參考第三方服務提供的 APIs,例如:Sentry APIs、GCP Logging APIs
- 抓到錯誤並送 Log:透過
try catch、Error Boundary等方式抓到錯誤資訊,並且與要送的其他資訊(網址、裝置、作業系統、版號等)整理後,利用封裝好的送 Log 的方法,將資料送到 Log Service。
第一步基本上看第三方服務提供的 APIs 文件做就對了,所以可以跳過這段XD,但如果你剛好要用 GCP Cloud Logging 可以參考參考。
至於我當時實作的團隊,為什麼選用 GCP Cloud Logging 呢?
- 金錢成本考量:當時所在的公司,算是 Google 代理商,可以用很低的成本使用 GCP Cloud 的大多服務。
- 技術成本考量:當時後端已經有用 GCP Cloud Logging,且其他團隊也用 GCP 相關服務,讓技術統一比較好管理。
所以當時就選擇用 GCP Cloud Logging,在此也會以 GCP Cloud Logging 作為簡要示範。
使用 GCP Cloud Logging 時,需要用到 Service account credential,可以把它“想像”成很重要的私鑰檔案,這把私鑰的權限可以開很大,大到全部 GCP 功能都可以用,也可以只鎖定在 Logging、Minotoring 這類本文所需的特定功能。
由於 Service account credential 並非本文重點,所以不再贅述,有興趣可以看 Service account credentials document,基本上最需要知道的是:GCP 強烈建議要在 Server 端夾帶 Service account credential 送 Log 才是安全的。
由於前端 Next.js 專案是有配置 Server 且此 Server 用量低,因此就直接在 Server 中開一個 /api/log API,讓前端錯誤先從 Clent 端透過 /api/log API 將 Log 送到 Server,再從 Server 帶著 Service account credential 透過 @google-cloud/logging API 送到 GCP Logging Service。
整理一下,流程是:
- Client 端抓到錯誤 =>
- 整理錯誤資訊,打
/api/logAPI 送到 Server 端 => - Server 端接收到錯誤資料 =>
- 在 Server 端打
@google-cloud/loggingAPI 送到 GCP Logging Service
實作的程式碼概念如下:
/* server.js file */
// ...(省略)
const express = require('express')
const next = require('next')
const { Logging } = require('@google-cloud/logging')
// For development mode, will set CREDENTIALS on server
// For production mode, will set CREDENTIALS during deploy step (not the focus of this article)
const isDevelopmentMode = process.env.NODE_ENV !== 'production'
if (isDevelopmentMode) {
process.env.GOOGLE_APPLICATION_CREDENTIALS = './xxx.secret.json'
}
// Implement "sendLogToGcpLogging" for Server to "send log to GCP"
async function sendLogToGcpLogging ({
severity = 'INFO',
logName = 'frontend-log',
logData = {}
}) {
const logging = new Logging()
const log = logging.log(logName)
// LogEntry Ref: https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry
const metadata = {
resource: { type: 'global' },
severity
}
const data = {
site: 'xxx',
appVersion: process.env.npm_package_version,
...logData
}
const entry = log.entry(metadata, data)
async function writeLog () {
await log.write(entry)
}
writeLog()
}
// ...(省略)
(async () => {
await app.prepare()
const server = express()
// ...(省略)
// Implement “/api/log” for Client side to "send log to Server”
server.post('/api/log', jsonParser, async (req, res) => {
if (isDevelopmentMode) {
// For development mode, will not actaully send log to GCP on default
return res.status(201).json({
success: 'Log entry send successfully on development mode.'
})
}
try {
if (!req.body) {
return res.status(400).json({
error: 'Invalid req body.'
})
}
const errorObject = req.body
// Trigger "sendLogToGcpLogging"
await sendLogToGcpLogging({
severity: errorObject.severity,
logName: errorObject.logName,
logData: errorObject.logData
})
return res.status(201).json({
success: 'Log entry created successfully.'
})
} catch (error) {
console.error('Error logging:', error)
return res.status(500).json({
error: 'Internal server error.'
})
}
})
// ...(省略)
})()
完成第一步「封裝送 Log 的方法」後,接著進行第二步「抓到錯誤並送 Log」,基本上就是在錯誤發生處,把要紀錄的所有資料整理後打 /api/log,以 ErrorBoundary 的範例而言,就是在 componentDidCatch(error){...} 中處理,如下:
/* ErrorBoundary.js file */
import ErrorFallback from './ErrorFallback'
import { connect } from 'react-redux'
import { ENVIRONMENT } from '@/config'
import { unAuthPost } from '@/lib/api/request'
import { checkIsClientSide, getDeviceInfo } from '@/lib/general/window'
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = {
hasError: false,
error: null
};
}
static getDerivedStateFromError(error) {
return { hasError: true, error };
}
// Catch error and send log to `/api/log`
componentDidCatch (error) {
if (checkIsClientSide()) {
const deviceInfo = getDeviceInfo()
const userInfo = this.props.user
unAuthPost(
'/api/log',
{
severity: 'CRITICAL',
logData: {
message: `${ENVIRONMENT} Unexpected Page Crash Error`,
pathName: window.location.pathname,
title: error.message,
stack: error.stack,
userId: userInfo.id,
companyId: userInfo.currentCompanyDetail.id,
deviceOS: deviceInfo?.os?.name,
deviceType: deviceInfo?.device?.type,
browserName: deviceInfo?.client?.name,
browserVersion: deviceInfo?.client?.version,
......
}
}
)
}
}
render () {
if (this.state.hasError) {
return (
<ErrorFallback
error={this.state.error}
resetError={() => {
this.setState({
hasError: false,
error: null
});
}}
/>
)
}
return this.props.children
}
}
const mapStateToProps = (state) => {
return { user: state.user }
}
export default connect(mapStateToProps, null)(ErrorBoundary)
其中如何打 API 送資料,就看自己專案的實作方式,每個專案都會有所差異。
成功後,就會在 GCP Logging Console 看到類似下圖的資料:
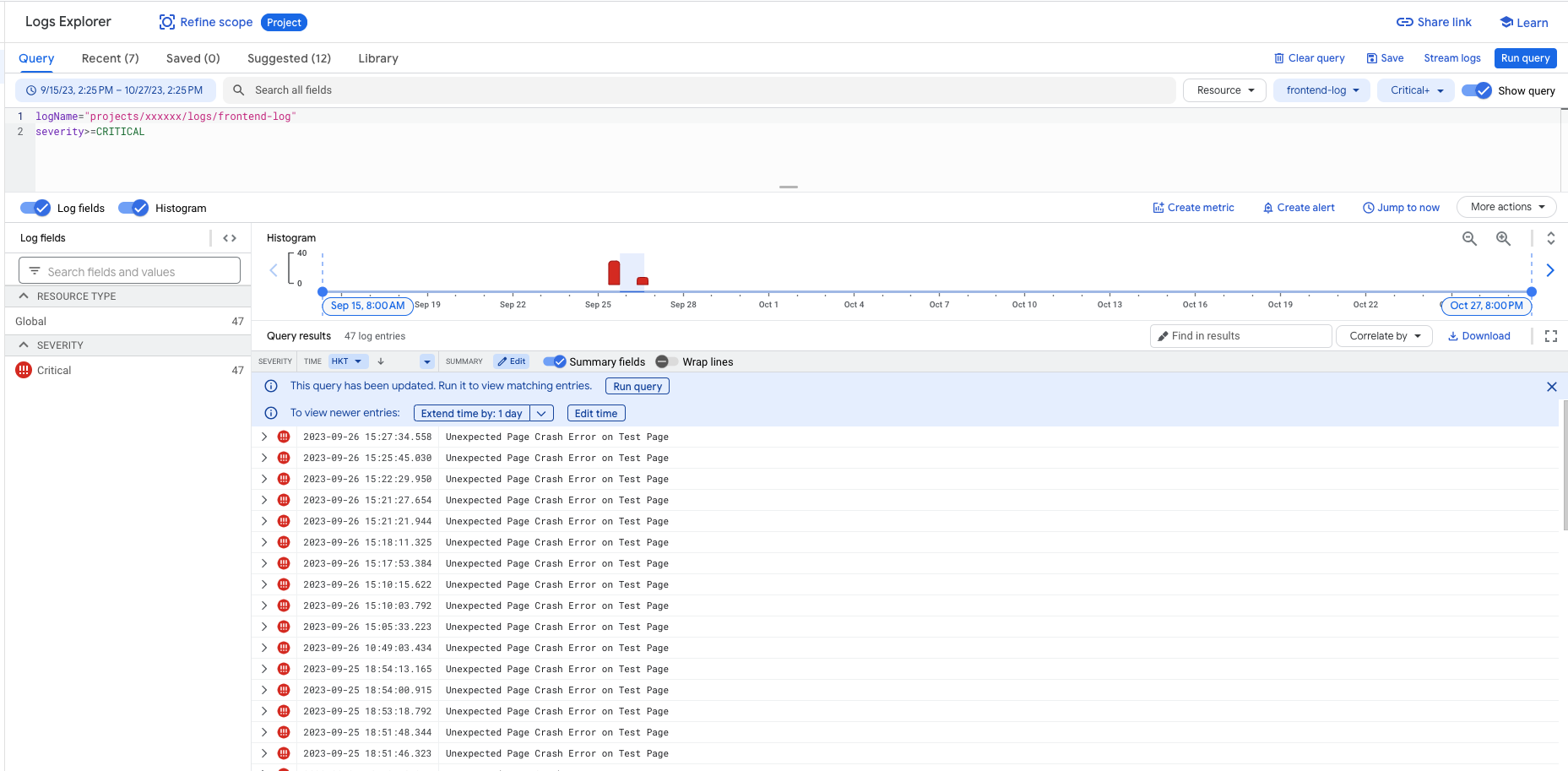 (GCP Logging Console 示意)
(GCP Logging Console 示意)
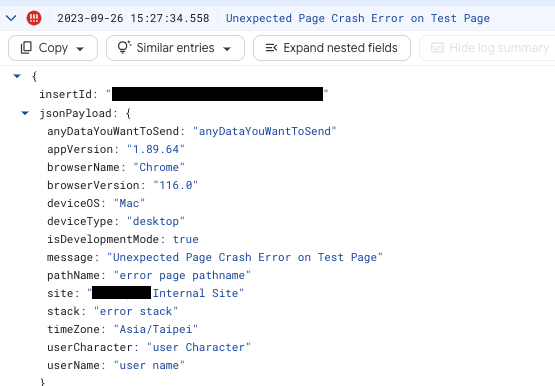 (單筆 Log 資料展開的示意)
(單筆 Log 資料展開的示意)
在上述的實作方式中,需要特別注意「如果大量錯誤發生,狂送 /api/log 時,會不會把前端 Server 打爆」,當時實作的產品有根據性質與資源配置,評估過發生 Sever 爆掉的機率極低。但如果是其他產品,例如:流量超大的產品之類,就需要另外處理很多細節。
總之要記得要針對自身產品狀況做評估,再決定該如何實作,效益才能最大化囉。
監控層級的處理
概念介紹
終於進入到最後一個環節,談談關於錯誤監控,或者說會更聚焦於錯誤警告(Alert)。
在這個層級當中,目標是化被動為主動,不需使用者反應,團隊就能主動發現錯誤、處理錯誤,這樣有幾個好處:
- 使用者發現錯誤之前,就已經修復完畢,使用者完全感受不到問題
- 使用者發現錯誤之前,就已經開始修復,使用者覺得修復得很快
- 產品經理預先知道錯誤發生,就能先準備如何應對來自上級或使用端的詢問
- ......
SLA(Service-Level Agreement, 服務等級協議) 在這裡是重要的指標,SLA 指得是產品提供給客戶的服務品質保證,具體來說如果產品對客戶保證的 SLA 為 99.5% 意味著:產品服務預計在一年中的 99.5% 的時間內是可用的,換算而言就是允許每年大約有 1.83 天(即 43.8 小時)的停機時間,無論是計劃內還是意外的狀況。
所以能否快速修復問題會是重要的關鍵之一。做好錯誤監控,也會讓 SLA 的達成更順利些。
我認為錯誤監控的警告設置,有個最重要的重點就是:要設置有意義的錯誤警告。
什麼是有意義的錯誤警告?就要「需要行動起來的警告」。如果每次跳錯誤警告根本沒人去看、不需要做事,錯誤警告就沒意義了。
舉例來說:想設置「API 發生錯誤時的錯誤警告」,那麼使用者登入時,輸入錯誤的帳號,這時候 API 報錯,需不需要跳錯誤警告?
不用,因為使用者很常輸入錯誤,但這是「正常行為」。可以每次輸入錯誤時,有錯誤 Log 的紀錄,如果有需要可以查詢; 但不需要每次發生輸入帳號錯誤時,就跳出警告通知給開發人員,因為開發人員其實也不需要做什麼。
當然如果有「不正常的行為」的連續行為發生,例如:一分鐘內登入 API 被連續打 100 次都失敗,需不需要跳錯誤警告?
需要,但是與上面的「API 發生錯誤時的錯誤警告」是兩者不同的警告,這時候應該會設定「被 DDoS 的錯誤警告」或「API 錯誤頻率太高的錯誤警告」之類,將錯誤警告做好分類也蠻重要的,才能讓開發者看到錯誤警告時,第一時間就知道發生什麼問題,以及行動起來。
 (Alert Policy 範例,會根據不同站台、類型的錯誤,設置不同的 Policy)
(Alert Policy 範例,會根據不同站台、類型的錯誤,設置不同的 Policy)
 (Slack Channel 範例,在通知頻道可以適度分類,藉此更快知道是哪種錯誤類型)
(Slack Channel 範例,在通知頻道可以適度分類,藉此更快知道是哪種錯誤類型)
錯誤監控和警告同樣是可以一直優化的流程,發現哪次重要的錯誤沒被警告到,下次就設定好新的警告; 有些總是虛晃一招的警告,下次就把它關閉。
當設置好錯誤監控後,大致的問題處理流程會是:
- 錯誤通知在 Slack 跳出(如下方附圖) =>
- 從錯誤 Log 中查看問題是什麼 =>
- 回報到產品經理與工程師都在的群組中,確認問題等級是否需要立刻修復 =>
- 如果需要立刻修就 hotfix; 不需要就排入下個 sprint 修 =>
- 檢討為什麼會發生問題、未來該如何避免
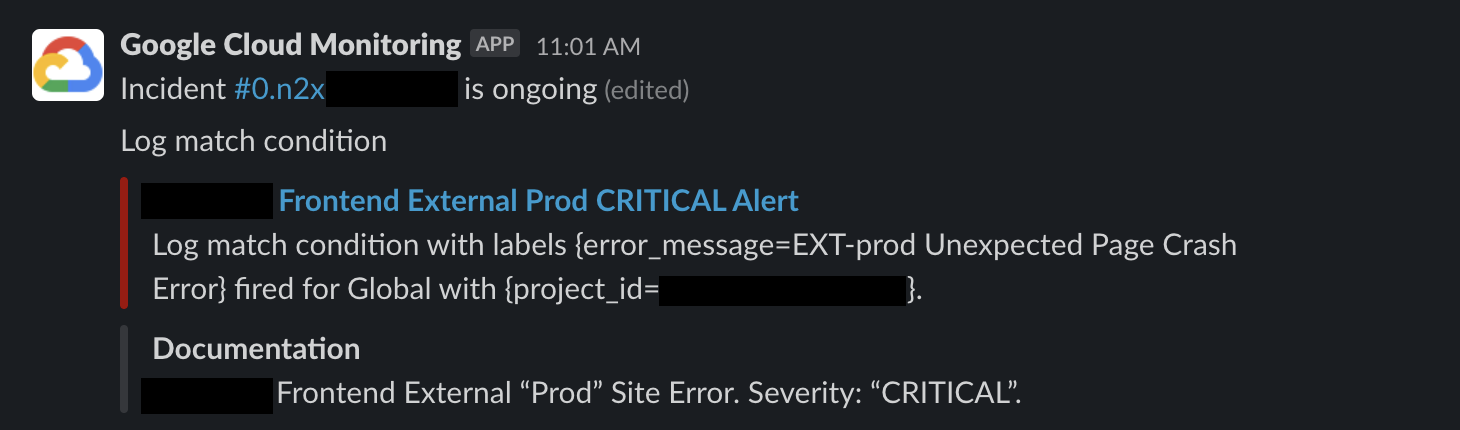 (Slack GCP Alert 示意,可以看到是 “CRITICAL” 嚴重錯誤,需立刻處理)
(Slack GCP Alert 示意,可以看到是 “CRITICAL” 嚴重錯誤,需立刻處理)
實作概要
實作上要看使用的是哪個「監控系統」與「通知系統」,在此簡單示範的是 GCP Monitoring 與 Slack。
選擇 GCP Monitoring 的原因,是和 GCP Logging 相同,就是金錢成本更低以及技術統一,不再重述。
選擇 Slack 的原因,是它與各大 APP 串接整合的很好,通常介面上點一點就串完了。
基本上兩者要串接在一起非常的方便,都是 GUI 上點一點就可以完成,而且網路文件、文章資源很多,在此不會說太多細節囉,主要只會稍微說明一下 GCP Alert Policy。
首先,要在 GCP Monitoring 的 Alert 中建置 Alert Policy,藉此設定「資料來源為何」、「警告發生的條件」、「警告頻率」等等,以設置「若發生對外站台(EXT)的 CRITICAL 層級錯誤時,要跳警告」為例:
- 資料來源:GCP Logging 的 Log
- 警告條件:當 Log 中,有包含 Severity 為 "CRITICAL" 就跳警告
- 警告頻率:每 5 分鐘跳一次警告
- 警告事件自動關閉頻率:3 days 沒再次發生就自動關閉
- 通知頻道:Slack #frontend-prod-error Channel
 (創建 Alert Policy 1: 在GCP Alert 頁面可點擊 Create Policy)
(創建 Alert Policy 1: 在GCP Alert 頁面可點擊 Create Policy)
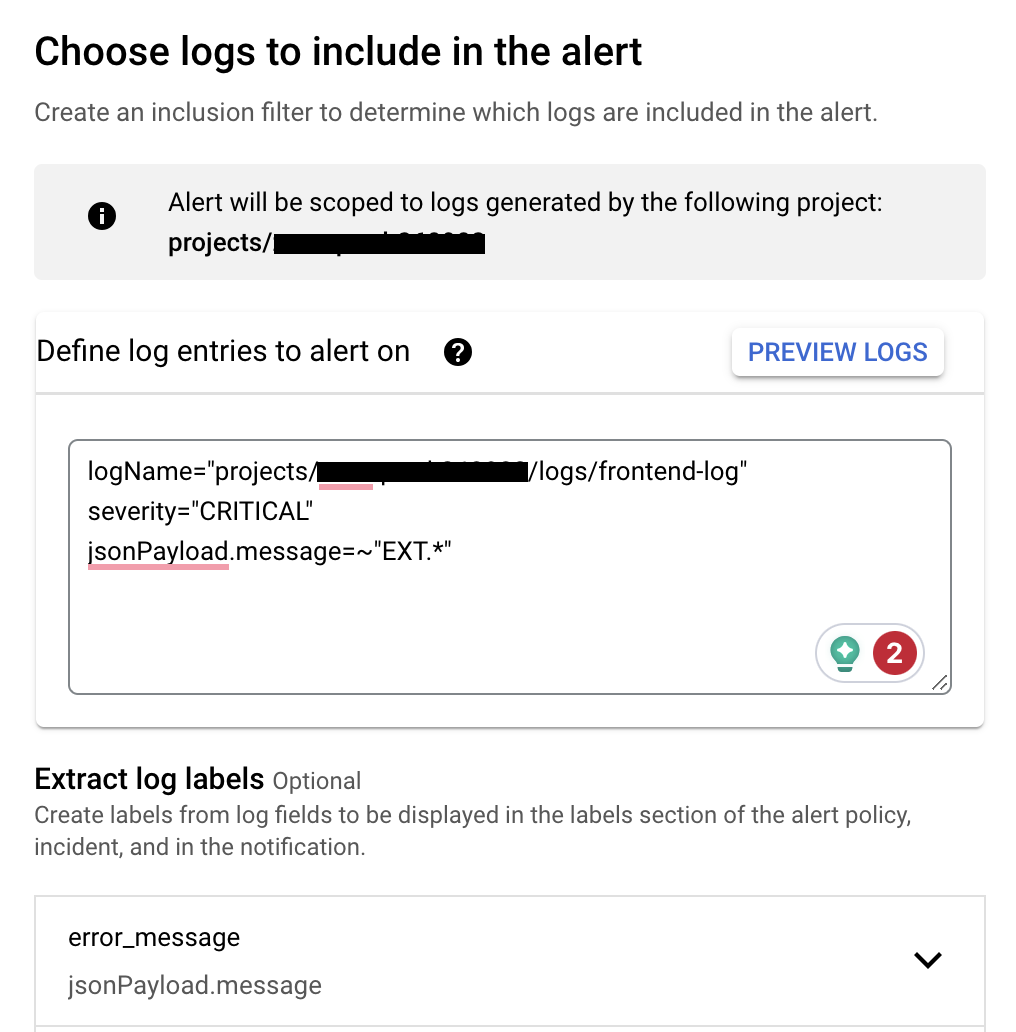 (創建 Alert Policy 2,創建過程中,可用 Logging query language 去篩選要跳警告的 Log)
(創建 Alert Policy 2,創建過程中,可用 Logging query language 去篩選要跳警告的 Log)
 (創建 Alert Policy 3,創建過程中,可選擇警告頻率與警告事件自動關閉頻率)
(創建 Alert Policy 3,創建過程中,可選擇警告頻率與警告事件自動關閉頻率)
 (創建 Alert Policy 4,創建過程中,可選擇通知的 Slack 頻道)
(創建 Alert Policy 4,創建過程中,可選擇通知的 Slack 頻道)
在所有資料填寫完畢後,案下畫面上的創建按鈕,就能創造一個 Alet Policy,未來只要有符合條件的 Log 發生時,就能會在所設定的 Slack Channel 看到警告哦。
如果需要更多實作細節,可以用中英文搜尋「GCP Monitoring Alert 與 Slack 串接步驟」或者問 ChatGPT4 就會有很多說明囉。
重點整理與回顧
寫一寫發現文章超長,如果你能閱讀到此算很有耐心啊。總之,至此應能更理解這張「基本的前端錯誤系統概念圖」!
用列點的方式整理重點概要:
- 前端錯誤處理系統包含「錯誤畫面」、「錯誤紀錄」、「錯誤監控」的項目。
- 當重要錯誤發生時,錯誤畫面會呈現在使用者面前; 錯誤紀錄會紀錄到 Log 服務中; 錯誤監控會跳出警告通知。
- 錯誤畫面:
- 要能讓使用者知道發生什麼、還可以做什麼。
- 要能讓開發者能獲得初步的除錯資訊,至少要有錯誤時間。
- 錯誤紀錄:
- 把錯誤發生當下的重點資料記錄下來,方便後續查詢。
- 不可以紀錄有資安疑慮的資訊。
- 錯誤監控:
- 化被動為主動,不需使用者反應,團隊就能主動發現錯誤、處理錯誤。
- 要設置「需要行動的警告」,如果每次跳錯誤警告沒人去看,錯誤警告就沒意義了。
- 所有錯誤流程,都可以持續改進,無須一次到位(通常也沒辦法),持續反思優化是很重要的。
最後稍微分享,當我們的產品在前端錯誤系統做完後,是真的有幫助到產品本身以及產品經理,隨意舉例像是:
- 有項目上去 Dev / Staging 後就不定期噴錯,藉此在上 Prod 前就修復。
- 有項目上去 Prod 後,就有少數錯誤“持續”發生,查找後發現 root cause 嚴重趕緊修復,在使用者反映前處理完畢。
- 產品經理認為,在前端錯誤系統上去後,她會更能知道產品現況,即便是有錯誤,也能夠提早應對之,更能對產品放心些。
另外,前端團隊自己上東西時當然也會比較放心些囉。
總之前端錯誤系統更完善後,是真的有帶來價值,順手紀錄分享,除了便於回顧外,也或許能為他人帶來價值囉。